











理解資訊如何穿越系統,是建立可靠軟體架構的根本。當我們使用資料流程圖(DFD)來繪製系統時,我們並非僅僅畫出方框與線條;我們實際上是在描繪資料本身的生命周期。分析資料流動路徑需要嚴謹地檢視資料的來源、轉換方式、暫存位置以及離開環境的途徑。此過程確保整個架構在完整性、效能與安全性上的穩定。
若無清晰的圖譜,資料可能遺失、重複或遭未授權存取。徹底的分析能在生產環境受影響前,揭露瓶頸、隱藏的相依性與潛在的失敗點。本指南探討以精確與清晰的方式剖析這些路徑的方法論。
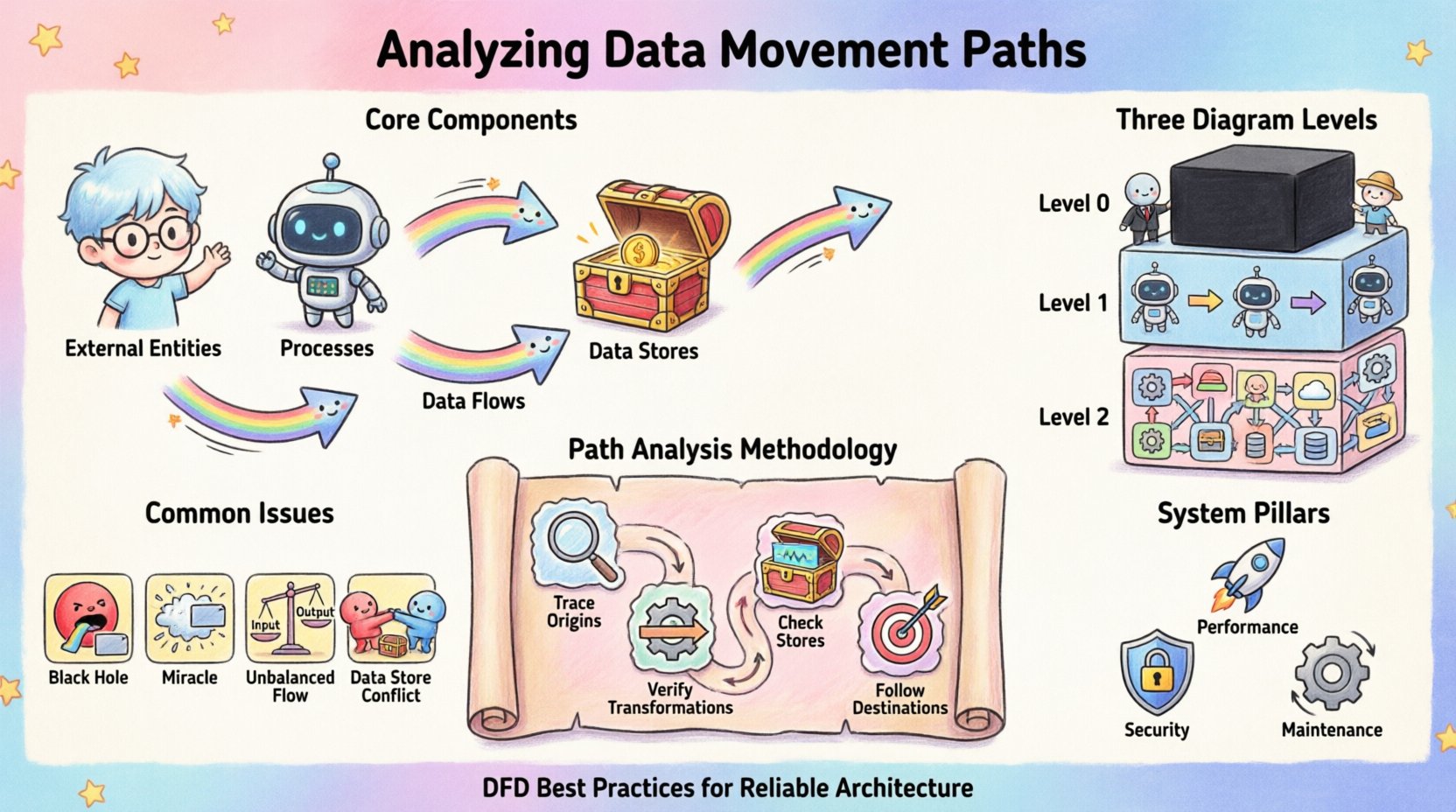
資料流動的核心元件 🧩
要有效分析流動,首先必須識別促成流動的各個獨特元件。每個DFD都依賴一致的術語來描述流程。忽略這些定義將導致模型出現模糊不清。
- 外部實體: 這些代表系統邊界以外的來源或目的地。它們啟動資料請求或接收處理後的輸出。範例包括人類使用者、其他系統或第三方服務。
- 處理程序: 這些是轉換動作。處理程序接收輸入資料,套用邏輯或規則,並產生輸出。它是系統內部變化的引擎。
- 資料儲存: 這些是資訊被儲存以供後續檢索的儲存庫。它們提供持久性,使資料能在處理程序執行結束後依然存在。
- 資料流: 這些是連接各元件的箭頭。它們代表資料封包或記錄在實體、處理程序與儲存之間實際移動的過程。
每個箭頭都必須有描述性的標籤,明確指出正在傳輸的資訊內容。模糊的標籤如「資訊」或「資料」會掩蓋傳輸的具體性質,使分析變得困難。
圖示中的細節層級 📊
資料流動很少是靜態的;它存在於各種抽象層級中。單一圖示無法捕捉每一比特的資訊。相反地,我們使用層級化的方法來分解系統。
1. 上下文圖(第0層)
最高層次的視圖將整個系統視為一個單一的黑箱。它顯示系統與外部實體的互動。這對於理解系統邊界至關重要。它回答的問題是:系統與外界交換什麼?
2. 第1層圖
在此層級,黑箱被拆解為主要的處理程序。此層揭示主要的子系統,以及高階資料在它們之間如何流動。它提供內部架構的整體視圖,而不陷入細節邏輯中。
3. 第2層圖及其以下
針對複雜的處理程序會進行進一步的分解。這些詳細視圖顯示特定的轉換與資料的細粒度流動。此層級對於識別特定的驗證步驟與錯誤處理機制至關重要。
在分析路徑時,各層級之間的一致性至關重要。進入第1層處理程序的資料,必須與離開它的資料相符。層級間的差異表示設計上存在缺口。
路徑分析的方法論 🔍
追蹤資料路徑是一項系統性的作業。它涉及從來源追蹤至終點的軌跡。此過程有助於識別邏輯錯誤與遺漏的連結。
步驟1:追蹤輸入來源
從外部實體開始。沿著箭頭進入系統。問這筆資料接下來會去哪裡?是流向處理程序還是儲存?若流向處理程序,該程序是否具備足夠資訊以運作?每個處理程序至少必須有一個輸入與一個輸出。
步驟2:驗證轉換
當資料進入處理程序後,分析其變化。輸出是否邏輯上源自輸入?有時,資料會出現在處理程序的輸出中,卻未出現在輸入中。這稱為「奇蹟」,表示遺漏了輸入,或存在應被記錄的硬編碼常數。
步驟3:檢查資料儲存
識別每一筆讀取與寫入操作。資料儲存不應成為死路。若資料流入儲存,則必須在某個時點有對應的資料流出,除非資料已被永久歸檔。確認圖示所暗示的資料結構與實際儲存需求相符。
步驟4:追蹤輸出目的地
處理後的資料會去哪裡?會返回給使用者嗎?會觸發另一個流程嗎?會離開系統邊界嗎?請確保每一個輸出路徑都已被納入考量。產生資料卻沒有目的地的孤兒流程,是設計不完整的徵兆。
常見的結構問題 ⚠️
在分析過程中,會出現一些特定模式,顯示設計上的缺陷。及早識別這些問題,可避免後續產生高昂的重構成本。
| 問題 | 描述 | 影響 |
|---|---|---|
| 黑洞 | 一個流程有輸入,但沒有輸出。 | 資料被消耗後消失無蹤。邏輯不完整。 |
| 奇蹟 | 一個流程有輸出,但沒有輸入。 | 資料憑空出現。邏輯未明確定義。 |
| 不平衡的流程 | 各層級之間的輸入與輸出資料不一致。 | 分解過程中資料完整性喪失。 |
| 資料儲存衝突 | 多個流程在未加鎖的情況下寫入同一個儲存區。 | 並發問題與資料損毀。 |
安全性與合規性考量 🔒
安全性不是附加功能;它是資料移動本身的一項屬性。分析資料路徑,可幫助我們識別敏感資訊存放與傳輸的位置。
識別敏感資料
追蹤個人識別資訊(PII)或財務紀錄。若敏感資料在流程之間移動,是否需要加密?若資料儲存在儲存區中,存取是否受到控制?圖示應突出顯示這些敏感資料流,例如使用不同的線條樣式或標籤。
存取控制點
每個流程都可能成為潛在的守門人。分析每個流程的驗證需求。資料流程圖是否暗示任何流程都能存取任何儲存區?這通常表示需要更嚴格的角色權限存取控制。
法規合規性
法規通常規定資料可存放的位置。例如,某些司法管轄區要求資料必須留在特定地理範圍內。任何跨越這些邊界的資料移動路徑都必須標記以供法律審查。圖示可作為合規架構的證據。
效能與優化 🚀
資料移動並非免費的。它會消耗頻寬、運算能力與時間。分析這些路徑有助於優化這些資源。
識別瓶頸
尋找具有多個高流量輸入與輸出的流程。這些流程很可能成為效能瓶頸。若單一流程在傳遞資料前需從五個不同來源整合資料,可能在負載下運作困難。建議將其拆分為平行流程。
延遲分析
計算資料到達目的地所需的跳數。每次跳躍都會引入延遲。如果使用者請求在回應結果前必須經過十個處理程序,系統會顯得遲緩。減少轉換次數可以提升回應速度。
減少冗餘
檢查重複的資料流。如果相同資訊被傳送至三個不同的處理程序,應考慮是否可共用同一個資料儲存空間。這能減少網路流量並確保一致性。
維持圖表準確性 🔄
圖表是一份活文件。隨著系統演進,路徑也會改變。維持準確性需要有紀律的方法。
版本控制
資料流結構的每一項變更都應進行版本控制。這讓團隊能夠追蹤特定路徑何時被修改。對於除錯與影響分析而言至關重要。
影響分析
在修改處理程序之前,應追蹤所有相關的資料流。更改一個處理程序可能會導致下游使用者中斷。圖表有助於呈現這些依賴關係。若資料儲存空間中的資料格式發生變更,所有讀取該資料的處理程序都必須更新。
文件標準
建立命名與標籤的規則。一致的命名慣例可讓新成員輕易閱讀圖表。應有明確的圖例,解釋用於安全或效能標記的特殊符號或線條類型。
與其他模型的整合 🤝
資料流程圖並非孤立存在。它們與其他建模技術相輔相成。
實體關係圖 (ERD)
雖然DFD著重於資料移動,ERD則著重於結構。交叉比對可確保流程中的資料流與資料庫中定義的資料結構相符。若某處理程序預期為「CustomerID」,但ERD中定義為「ClientNum」,則存在不一致。
狀態轉移圖
DFD顯示資料移動的內容,而狀態圖則顯示移動的時機。結合兩者有助於理解資料移動如何觸發狀態變更。例如,「付款已收到」的資料流可能觸發狀態從「待處理」變為「已出貨」。
分析實務的結論 ✅
分析資料移動路徑的紀律在於清晰與控制。它能將抽象的需求轉化為具體的架構決策。透過嚴謹地追蹤每一條箭頭並驗證每一項轉換,架構師能建構出具韌性且易於理解的系統。
此實務要求細心留意。必須質疑每一個關於資料來源與去向的假設。若執行得當,所產生的圖表將成為開發、測試與維護的藍圖。它成為商業利害關係人與技術團隊之間的共通語言,確保所有人皆理解資料的旅程。
隨著系統變得越來越複雜,清晰的映射需求也日益增加。一份經過仔細分析的資料流程圖,是對軟體長期穩定性的投資。它能降低資料遺失、安全漏洞與效能退化的風險。透過遵守這些分析標準,團隊能確保系統在擴展時仍保持穩健。