











Целостность данных зависит от прозрачности. Без чёткой карты движения информации через систему организации действуют вслепую. Отслеживание происхождения данных предоставляет такую карту, фиксируя путь от источника до потребления. Диаграммы потоков данных служат основным визуальным языком для этой задачи. Они преобразуют сложные технические процессы в понятные структуры, позволяя командам точно отслеживать преобразования и зависимости. Такой подход гарантирует, что каждая единица данных может быть учтена, что способствует соблюдению нормативных требований, отладке и стратегическому принятию решений.
Процесс включает в себя больше, чем просто рисование линий между блоками. Требуется глубокое понимание базовой архитектуры, логики, управляющей преобразованиями, и механизмов хранения данных. Используя стандартизированные методы построения диаграмм, технические команды могут создать живую документацию, которая развивается вместе с инфраструктурой. Данный документ описывает методологию реализации отслеживания происхождения данных с помощью диаграмм потоков, делая акцент на чёткости, точности и долгосрочной поддерживаемости.
Понимание происхождения данных 🧬
Происхождение данных — это история данных. Оно фиксирует источники, перемещения и преобразования, которым подвергается данные на протяжении всего жизненного цикла. Представьте каплю воды, попадающую в речную систему; происхождение отслеживает, откуда она пришла, какие притоки она прошла и куда в конечном итоге вытекает. В цифровом контексте это означает знать, какая таблица базы данных сгенерировала запись, какой скрипт её обработал и какой дашборд отображает итоговый показатель.
Установление происхождения данных имеет критическое значение по нескольким причинам. Во-первых, оно помогает в устранении неполадок. Когда число в отчёте кажется неверным, происхождение позволяет инженерам отследить значение назад, чтобы определить, где возникла расхождение. Во-вторых, оно способствует соблюдению нормативных требований. Законы, касающиеся конфиденциальности данных, часто требуют от организаций точно знать, где хранится персональная информация и как она используется. Наконец, оно формирует доверие. Заинтересованные стороны с большей вероятностью будут полагаться на аналитику, если понимают источник и логику обработки данных.
Происхождение данных можно разделить на два основных типа: логическое и физическое. Логическое происхождение описывает концептуальное перемещение данных, например: «ID клиента перемещается из отдела продаж в отдел бухгалтерии». Физическое происхождение детализирует конкретные технические шаги, например: «Столбец 5 из таблицы A извлекается с помощью SQL-запроса B в столбец 3 таблицы C». Диаграммы потоков эффективно соединяют эти два типа, предоставляя визуальное представление, которое удовлетворяет как бизнес-заинтересованным сторонам, так и техническим инженерам.
Роль диаграмм потоков данных 📊
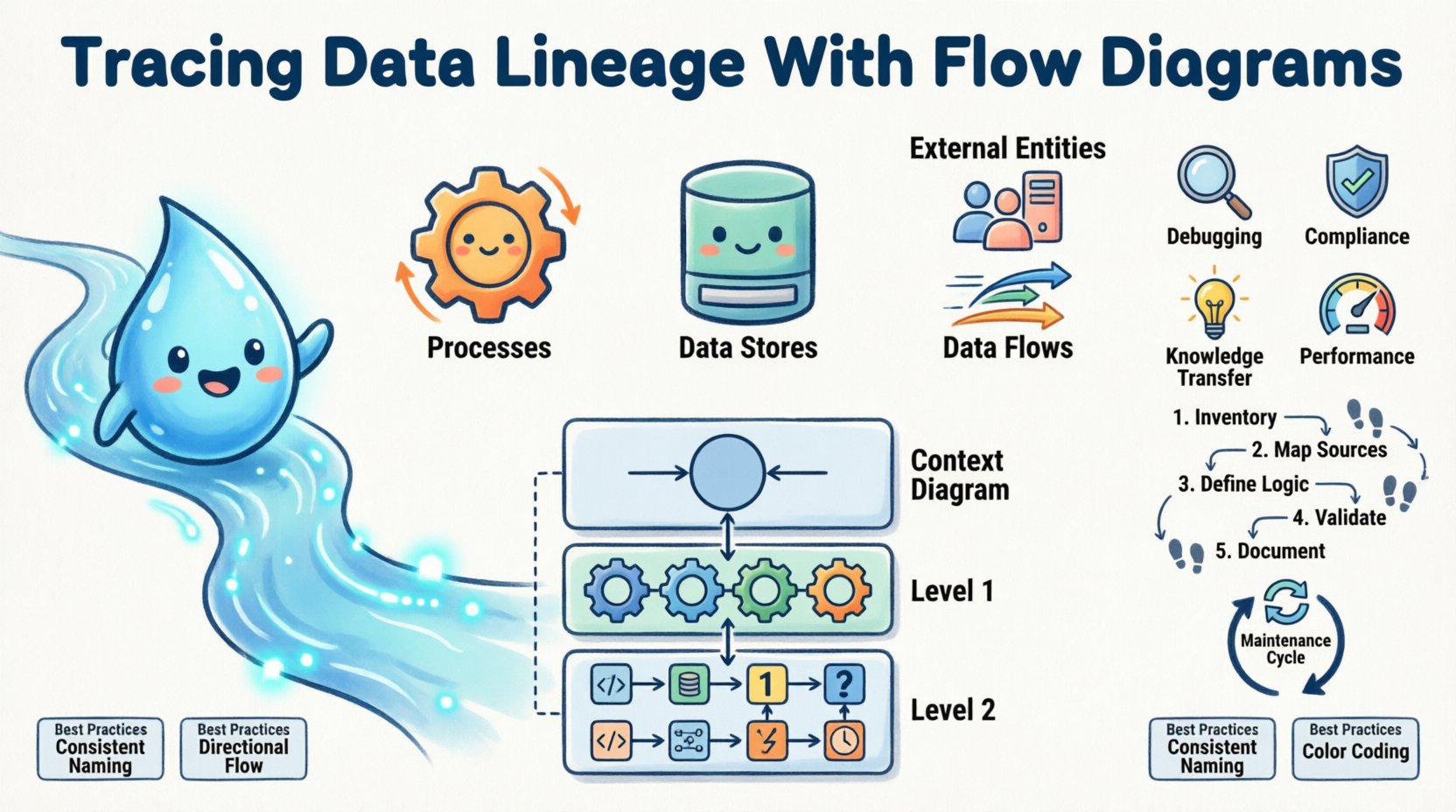
Диаграммы потоков данных (DFD) — это графическое представление движения данных через систему. В отличие от диаграмм сущность-связь, которые фокусируются на статических отношениях между объектами данных, DFD акцентируют внимание на динамическом потоке и обработке информации. Они разбивают сложные системы на управляемые компоненты, что делает их идеальными для отслеживания происхождения данных.
Стандартная DFD состоит из четырёх основных элементов:
- Процессы: Действия, преобразующие данные. Обычно они изображаются в виде кругов или закруглённых прямоугольников. Примеры: «Рассчитать налог» или «Агрегировать данные по продажам».
- Хранилища данных: Где хранятся данные. Это открытые прямоугольники, представляющие базы данных, файлы или очереди.
- Внешние сущности: Источники или пункты назначения за пределами границ системы. К этой категории часто относятся пользователи, другие системы или регулирующие органы.
- Потоки данных: Стрелки, соединяющие элементы, указывающие направление и содержание перемещения данных.
При использовании для отслеживания происхождения данных эти элементы становятся узлами в более крупном графе. Соединения показывают путь. Соблюдая стандарты DFD, команды обеспечивают единообразие. Процесс на одной диаграмме следует тем же визуальным правилам, что и процесс на другой, что снижает когнитивную нагрузку для любого, кто просматривает документацию.
Уровни детализации диаграмм 🛠️
Для управления сложностью диаграммы потоков данных часто создаются на разных уровнях абстракции. Эта иерархия позволяет заинтересованным сторонам фокусироваться на конкретных областях, не перегружаясь всей архитектурой системы. Стандартный подход включает три уровня детализации.
| Уровень | Описание | Сценарий использования |
|---|---|---|
| Диаграмма контекста (уровень 0) | Обзор высокого уровня, показывающий систему как единый процесс и её взаимодействие с внешними сущностями. | Краткие обзоры для руководства и планирование архитектуры на высоком уровне. |
| Диаграмма уровня 1 | Разбивает основной процесс на основные подпроцессы и хранилища данных. | Проектирование системы и выявление ключевых точек взаимодействия с данными. |
| Диаграмма уровня 2 | Дальнейшее разбиение конкретных процессов уровня 1 на детальные шаги. | Техническая реализация, проверка кода и детальная аудиторская проверка. |
Такой иерархический подход предотвращает, чтобы диаграмма стала непонятной. Одна страница, показывающая каждый SQL-соединение и вызов API, была бы хаотичной. Вместо этого диаграмма контекста даёт общую картину, а диаграммы уровня 2 обеспечивают необходимую детализацию для инженерных задач. При отслеживании происхождения данных часто требуется перекрёстная проверка этих уровней. Запрос на диаграмме уровня 2 может быть обобщён как один процесс на диаграмме уровня 1.
Шаги по реализации отслеживания происхождения данных 📝
Создание точной карты происхождения данных требует системного подхода. Случайное рисование приводит к несогласованности и пропущенным связям. Ниже перечислены шаги, описывающие надежный рабочий процесс по созданию и поддержанию диаграмм потоков данных для отслеживания происхождения.
1. Инвентаризация существующих активов
Прежде чем рисовать, необходимо знать, что существует. Составьте список всех баз данных, хранилищ данных, серверов приложений и инструментов отчетности, участвующих в процессе. Определите основные источники данных, такие как транзакционные системы или внешние API. Этот список определяет границы вашей диаграммы. Без полного списка в карте происхождения будут пробелы, что приведет к незамеченным участкам при управлении данными.
2. Сопоставление источников данных с пунктами назначения
Начните с источника. Определите первоначальную точку входа данных. Отслеживайте их вперед до первого этапа обработки. Зафиксируйте логику преобразования. Скрипт очищает данные? Представление фильтрует определённые строки? Запишите это на уровне процесса. Продолжайте отслеживание до достижения конечного пункта назначения, например, панели бизнес-аналитики или системы архивного хранения.
3. Определение логики преобразования
Данные редко остаются неизменными. Они агрегируются, объединяются или вычисляются. Эти преобразования являются ключевыми точками в цепочке происхождения. Зафиксируйте конкретные правила, применяемые к данным. Например: «Пустые значения в столбце X заменяются на 0» или «Временные метки преобразуются из UTC в местное время». Такая детализация необходима для отладки. Если отчет на нижнем уровне показывает неожиданные значения, знание правила преобразования позволит воспроизвести ошибку в тестовой среде.
4. Проверка с техническими командами
Диаграмма, нарисованная в изоляции, подвержена ошибкам. Проверьте черновик вместе с инженерами, создавшими потоки данных, и аналитиками, использующими данные. Они могут выявить пропущенные этапы или неверные предположения. Такое сотрудничество гарантирует, что диаграмма отражает реальность, а не только теоретический дизайн. Проверка — важный этап для поддержания целостности документации по происхождению данных.
5. Документирование метаданных
Привяжите метаданные к элементам диаграммы. К ним относятся номера версий, имена владельцев и даты создания. Потоки данных со временем меняются. Процесс может быть переработан в следующем квартале. Метаданные позволяют отслеживать историю самой диаграммы, обеспечивая понимание, какая версия карты происхождения была активна в определённый период аудита.
Преимущества структурированного отслеживания происхождения данных 🏗️
Вложение времени в детальные диаграммы потоков данных приносит ощутимую отдачу на всех уровнях организации. Преимущества выходят за рамки простой документации.
- Снижение времени на отладку: Когда возникают ошибки, инженеры тратят меньше времени на поиск истинной причины. Диаграмма выступает в роли руководства, прямо указывая на наиболее вероятную зону сбоя.
- Улучшенный анализ последствий: Если предлагается изменение, например, изменение имени столбца, карта происхождения данных показывает точно, какие отчёты и последующие процессы будут нарушены. Это предотвращает случайные сбои.
- Соответствие регуляторным требованиям: Аудиторы требуют доказательства обработки данных. Диаграммы потоков данных предоставляют чёткий визуальный след аудита, удовлетворяющий требованиям к конфиденциальности и безопасности данных.
- Обмен знаниями: Новые члены команды могут быстро понять архитектуру системы. Вместо того чтобы полагаться на «племенные знания», они могут изучать диаграммы, чтобы понять, как данные проходят через организацию.
- Оптимизированная производительность: Анализ потока часто выявляет узкие места. Если данные слишком долго ждут в определённом хранилище или процессе, диаграмма указывает, где следует сосредоточить усилия по оптимизации.
Поддержание диаграмм 🔄
Карта происхождения данных — это не разовое задание. Системы развиваются. Добавляются новые источники данных, а старые процессы упраздняются. Если диаграммы не обновляются, они становятся вводящими в заблуждение. Поддержание точности требует дисциплинированного подхода к управлению изменениями.
Каждый раз, когда изменяется поток данных, диаграмма должна быть пересмотрена. Это должно быть частью чек-листа развертывания. Если интегрируется новый API, необходимо добавить внешний объект и поток данных. Если меняется логика преобразования, описание блока процесса должно быть обновлено. Рассматривая диаграмму как код, вы гарантируете, что она останется надёжным ресурсом.
Автоматизация может помочь в поддержании. Некоторые платформы позволяют генерировать диаграммы на основе репозиториев метаданных. Хотя ручной обзор по-прежнему необходим, автоматизация снижает нагрузку по поддержанию визуального представления в согласии с технической реальностью. Однако полная зависимость от автоматизации может упустить бизнес-контекст, поэтому человеческий контроль остаётся жизненно важным.
Решение сложности ⚖️
В крупных предприятиях часто возникают сложные экосистемы данных. Тысячи таблиц и сотни процессов могут сделать одну диаграмму чрезмерно перегруженной. В таких случаях ключевым является модульность. Разбейте цепочку происхождения на логические области. Создайте отдельные диаграммы для данных о продажах, данных о клиентах и финансовых данных. Свяжите их там, где они пересекаются, но сохраняйте основные представления сфокусированными.
Другая проблема — работа с устаревшими системами. Старые системы могут не иметь метаданных, необходимых для автоматического отслеживания. В таких случаях требуется ручная реконструкция. Проведите интервью с первоначальными разработчиками или изучите старую документацию, чтобы вывести логику потока. Будьте прозрачны в отношении этих пробелов. Отметьте области неопределённости на диаграмме, чтобы показать, где требуется дополнительное исследование.
Лучшие практики для ясности 🚀
Чтобы диаграммы выполняли свою функцию, придерживайтесь этих рекомендаций по дизайну и представлению.
- Согласованное наименование: Используйте стандартные названия для процессов и хранилищ данных на всех диаграммах. Избегайте сокращений, которые могут запутать читателей.
- Направленный поток: Располагайте диаграммы так, чтобы поток был логичным слева направо или сверху вниз. Это соответствует естественным паттернам чтения.
- Цветовая кодировка: Используйте цвета для обозначения статуса. Например, зелёный — для активных процессов, красный — для устаревших, жёлтый — для тех, которые требуют проверки.
- Слоистость: Держите высокий уровень обзора отдельно от детального. Не загромождайте основную диаграмму каждым отдельным сопоставлением полей.
- Управление доступом: Убедитесь, что диаграммы доступны тем, кто в них нуждается. Командам безопасности может потребоваться видеть потоки данных, включающие конфиденциальную информацию, в то время как разработчикам нужно видеть техническую реализацию.
Заключительные соображения 🔍
Отслеживание происхождения данных с помощью диаграмм потоков — это дисциплина, сочетающая техническую точность и чёткую коммуникацию. Она превращает абстрактные перемещения данных в конкретные визуальные модели. Следуя установленным стандартам и поддерживая строгий цикл обновлений, организации могут достичь высокого уровня прозрачности данных. Эта прозрачность является фундаментом современного управления данными.
Вложения, необходимые для создания и поддержания этих диаграмм, окупаются за счёт снижения рисков и повышения эффективности. По мере роста объёмов данных и ужесточения регуляторных требований способность отслеживать происхождение и путь данных станет ещё более критичной. Инвестирование в чёткие и точные диаграммы потоков сегодня готовит организацию к вызовам завтрашнего дня. Цель заключается не просто в документировании системы, а в глубоком понимании её, достаточном для постоянного улучшения.