











एक डेटा फ्लो डायग्राम, जिसे अक्सर DFD के रूप में संक्षिप्त किया जाता है, सिस्टम विश्लेषण और डिजाइन में एक महत्वपूर्ण दृश्य उपकरण के रूप में कार्य करता है। यह एक सिस्टम के माध्यम से जानकारी के प्रवाह को नक्शा बनाता है, जो डेटा के इनपुट से आउटपुट तक गति को दर्शाता है। नियंत्रण तर्क पर ध्यान केंद्रित करने वाले फ्लोचार्ट्स के विपरीत, एक DFD डेटा की गति पर ध्यान केंद्रित करता है। यह अंतर वास्तुकारों और विश्लेषकों के लिए महत्वपूर्ण है जिन्हें एक सिस्टम के तत्व को समझने की आवश्यकता होती है बिना निष्पादन के समय या शर्तों में फंसे रहने के बिना।
एक DFD बनाने के लिए एक संरचित दृष्टिकोण की आवश्यकता होती है। यह केवल आकृतियां बनाने के बारे में नहीं है; यह प्रक्रिया के तर्क और डेटा अखंडता के मॉडलिंग के बारे में है। चाहे आप एक नए सॉफ्टवेयर एप्लिकेशन का डिजाइन कर रहे हों, मौजूदा वर्कफ्लो का ऑडिट कर रहे हों, या व्यवसाय प्रक्रियाओं का नक्शा बना रहे हों, एक अच्छी तरह से निर्मित डायग्राम स्पष्टता प्रदान करता है। यह स्टेकहोल्डर्स को सिस्टम की सीमाओं को देखने और यह पहचानने में मदद करता है कि डेटा कहां से आता है और कहां भंडारित किया जाता है।
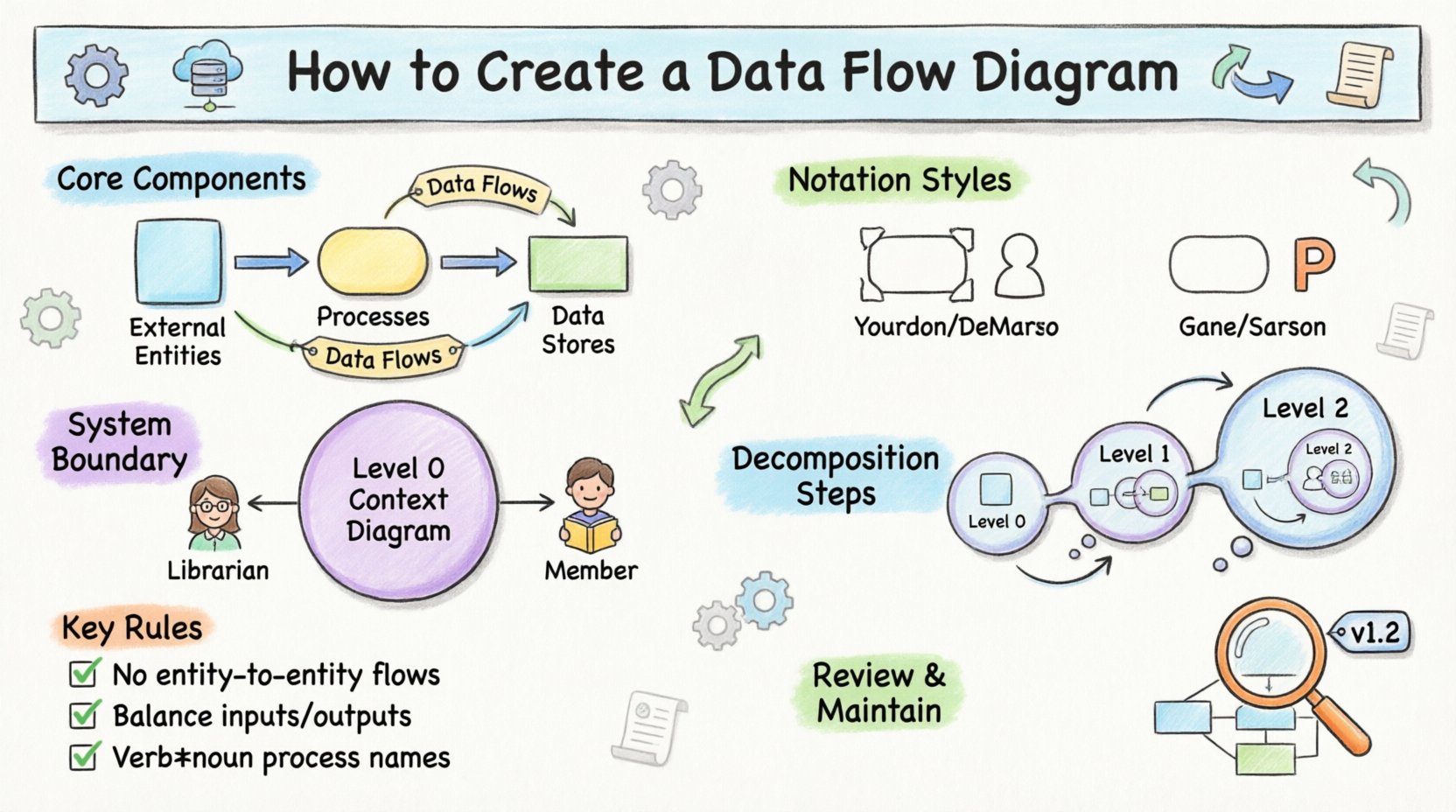
मूल घटकों को समझना 🧩
रेखाओं और बॉक्स को बनाने से पहले, आपको मूल निर्माण तत्वों को समझना होगा। प्रत्येक DFD में चार प्राथमिक तत्व होते हैं। इन घटकों को पहचानने से यह सुनिश्चित होता है कि डायग्राम संगत और पढ़ने योग्य बना रहे।
- बाहरी एंटिटीज: ये डेटा के स्रोत या गंतव्य हैं। वे सिस्टम की सीमा के बाहर मौजूद होते हैं। एक एंटिटी एक उपयोगकर्ता, एक अन्य सिस्टम या एक संगठन हो सकती है। डायग्राम में, इन्हें आमतौर पर वर्ग या वृत्त के रूप में दर्शाया जाता है।
- प्रक्रियाएं: यहीं कार्य होता है। प्रक्रियाएं इनपुट डेटा को आउटपुट डेटा में बदलती हैं। वे डेटा पर किए गए कार्य का प्रतिनिधित्व करती हैं। एक प्रक्रिया में कम से कम एक इनपुट और एक आउटपुट होना चाहिए। इन्हें आमतौर पर गोल किनारों वाले आयत या वृत्त के रूप में बनाया जाता है।
- डेटा स्टोर्स: ये डेटा के बाद के उपयोग के लिए रखे जाने के स्थान का प्रतिनिधित्व करते हैं। इन्हें भौतिक डेटाबेस, फाइल बॉक्स या यहां तक कि ईमेल इनबॉक्स भी हो सकते हैं। इन्हें कोई क्रिया शुरू नहीं करते, लेकिन जानकारी को रखते हैं। डेटा स्टोर्स को आमतौर पर खुले छोर वाले आयत या समानांतर रेखाओं के रूप में दर्शाया जाता है।
- डेटा प्रवाह: ये घटकों को जोड़ने वाली तीर हैं। वे डेटा की गति की दिशा दिखाते हैं। प्रत्येक तीर को स्थानांतरित की जा रही डेटा के नाम के साथ लेबल किया जाना चाहिए।
ध्यान देने योग्य बात यह है कि एक प्रक्रिया के बीच न होने पर डेटा एक एंटिटी से दूसरी एंटिटी में सीधे नहीं जा सकता है, न ही डेटा स्टोर से एंटिटी में बिना प्रक्रिया के जा सकता है। इन नियमों के कारण मॉडल की तार्किक अखंडता बनी रहती है।
नोटेशन शैली का चयन करना 🖊️
DFD बनाने के लिए दो मुख्य विधियां हैं। यद्यपि इनकी तार्किक बुनियाद एक जैसी है, लेकिन उनकी दृश्य प्रस्तुति भिन्न होती है। सही विकल्प का चयन टीम की पसंद या विशिष्ट उद्योग मानक पर निर्भर करता है।
| विशेषता | यौरडॉन और डेमार्को | गेन और सर्सन |
|---|---|---|
| प्रक्रियाएं | गोल वृत्त | गोल किनारों वाले आयत |
| डेटा स्टोर्स | खुले छोर वाले आयत | मोटे किनारों वाले खुले छोर वाले आयत |
| डेटा प्रवाह | वक्र तीर | वक्र तीर |
| बाहरी एंटिटीज | आयत | आयत |
यूरडॉन और डेमार्को शैली अक्सर पुरानी पद्धतियों से जुड़ी होती है, जबकि गेन और सर्सन का उपयोग आधुनिक संरचित विश्लेषण में व्यापक रूप से किया जाता है। आकृति के चयन के बावजूद, सुसंगतता महत्वपूर्ण है। एक ही दस्तावेज में शैलियों को मिलाना पाठकों को भ्रमित कर सकता है।
प्रणाली सीमा को परिभाषित करना 🚧
आरेख बनाने का पहला चरण सीमा को परिभाषित करना है। आपको यह तय करना होगा कि प्रणाली के अंदर क्या है और बाहर क्या है। इसे अक्सर एक संदर्भ आरेख (Context Diagram) बनाकर किया जाता है, जिसे लेवल 0 DFD भी कहा जाता है।
एक संदर्भ आरेख पूरी प्रणाली को एकल प्रक्रिया के रूप में दर्शाता है। यह प्रणाली और बाहरी एकाधिकारियों के बीच उच्च स्तर के बातचीत को दर्शाता है। इससे प्रणाली में प्रवेश करने वाले और बाहर निकलने वाले डेटा का एक पक्षी की आंख के दृष्टिकोण मिलता है। इसे बनाते समय केवल इनपुट और आउटपुट पर ध्यान केंद्रित करें। अभी आंतरिक प्रक्रियाओं का विवरण नहीं दें।
उदाहरण के लिए, एक पुस्तकालय प्रणाली पर विचार करें। प्रणाली एकल वृत्त है। बाहरी एकाधिकारी में “पुस्तकालय अधिकारी” और “सदस्य” शामिल हो सकते हैं। डेटा प्रवाह में “पुस्तक लेने का अनुरोध” प्रणाली में प्रवेश कर सकता है और “ऋण प्राप्ति प्रमाणपत्र” इससे बाहर निकल सकता है। यह सरल दृष्टिकोण अधिक विस्तृत विश्लेषण के लिए आधार तैयार करता है।
प्रक्रिया को विभाजित करना 🔄
जब संदर्भ स्थापित हो जाता है, तो प्रणाली को विभाजित करने की आवश्यकता होती है। इस प्रक्रिया को विभाजन (decomposition) कहा जाता है। इसमें संदर्भ आरेख से एकल प्रक्रिया को बहुत से उपप्रक्रियाओं में विस्तारित करना शामिल है। इससे लेवल 1 DFD बनता है।
विभाजन की देखभाल की आवश्यकता होती है। आप बिना किसी तर्क के यादृच्छिक प्रक्रियाएं जोड़ नहीं सकते। प्रत्येक उपप्रक्रिया को विशिष्ट डेटा परिवर्तनों को संभालना चाहिए। यदि डेटा प्रवाह एक उपप्रक्रिया में प्रवेश करता है, तो इसका एक विशिष्ट आउटपुट होना चाहिए। यदि डेटा संग्रहीत किया जाता है, तो इसे डेटा स्टोर से जोड़ा जाना चाहिए।
विभाजन के लिए मुख्य चरण
- उप-प्रक्रियाओं की पहचान करें: मुख्य प्रक्रिया को देखें। यह कौन-कौन से अलग-अलग कार्य करती है? इन कार्यों को अलग-अलग वृत्तों या आयतों में विभाजित करें।
- डेटा स्टोर को जोड़ें: यह तय करें कि जानकारी कहां संग्रहीत की जाती है। यदि कोई कार्य रिकॉर्ड को अपडेट करता है, तो डेटा स्टोर तक एक प्रवाह बनाएं।
- डेटा प्रवाह को बेहतर बनाएं: सुनिश्चित करें कि प्रत्येक तीर को लेबल किया गया हो। लेबल एक्रियन के बजाय डेटा का वर्णन करना चाहिए। उदाहरण के लिए, “कस्टमर ऑर्डर” का उपयोग करें, “ऑर्डर भेजें” के बजाय।
- सुसंगतता की जांच करें: सुनिश्चित करें कि लेवल 1 आरेख में डेटा प्रवाह, लेवल 0 आरेख में मुख्य प्रक्रिया के इनपुट और आउटपुट के साथ मेल खाते हैं।
इस प्रक्रिया को आगे भी जारी रखा जा सकता है। यदि लेवल 1 प्रक्रिया बहुत जटिल है, तो इसे लेवल 2 DFD में और विभाजित किया जा सकता है। इस पुनरावृत्तिक विभाजन के कारण विश्लेषकों को विशिष्ट क्षेत्रों पर ध्यान केंद्रित करने की अनुमति मिलती है बिना समग्र संदर्भ के खोए बिना।
आरेख बनाने और संतुलन के नियम ⚖️
DFD निर्माण को नियंत्रित करने वाले कठोर नियम हैं। इन नियमों के उल्लंघन से आरेख अमान्य हो सकता है। सबसे महत्वपूर्ण अवधारणा “संतुलन” है।
संतुलन का अर्थ है कि मुख्य प्रक्रिया के इनपुट और आउटपुट को उसकी उपप्रक्रियाओं के इनपुट और आउटपुट के साथ मेल बैठाना है। यदि लेवल 0 प्रक्रिया का इनपुट “ऑर्डर” है, तो लेवल 1 आरेख में उसी “ऑर्डर” डेटा को एक उपप्रक्रिया में प्रवेश करते हुए दिखाना होगा। आप निचले स्तर पर नए डेटा को नहीं जोड़ सकते जो ऊपरी स्तर पर उपलब्ध नहीं थे, बशर्ते कि वह एक तार्किक विवरण हो।
अतिरिक्त आरेख नियम
- एकाधिकारियों के बीच कोई डेटा प्रवाह नहीं: डेटा किसी प्रक्रिया से गुजरना चाहिए। यह एक बाहरी एकाधिकारी से दूसरे बाहरी एकाधिकारी तक सीधे नहीं जा सकता।
- डेटा स्टोर के बीच कोई डेटा प्रवाह नहीं: डेटा स्टोर स्थिर डेटा को रखते हैं। उनके बीच गतिशीलता के लिए एक प्रक्रिया की आवश्यकता होती है जो डेटा को परिवर्तित या स्थानांतरित करे।
- प्रक्रिया के बिना किसी डेटा स्टोर में डेटा प्रवाह या बाहर निकलना नहीं: एक स्टोर अपने आप डेटा उत्पन्न या प्राप्त नहीं कर सकता। एक प्रक्रिया को इंटरैक्शन को नियंत्रित करना चाहिए।
- प्रक्रिया नामकरण: प्रक्रियाओं के नाम एक क्रिया और एक संज्ञा के साथ रखें। इससे क्रिया स्पष्ट हो जाती है, जैसे “कर की गणना” या “इन्वेंटरी अपडेट”।
- डेटा प्रवाह नामकरण: प्रवाहों के नाम एक संज्ञा वाक्यांश के साथ रखें। इससे सामग्री स्पष्ट हो जाती है, जैसे “इन्वॉइस विवरण” या “भुगतान पुष्टि”।
समीक्षा और सुधार 🧐
जब आरेख ड्राफ्ट कर लिया जाता है, तो समीक्षा चरण अनिवार्य होता है। इसमें त्रुटियों, लापरवाहियों और स्पष्टता की समस्याओं की जांच करना शामिल है। हितधारकों को आरेख की समीक्षा करनी चाहिए ताकि यह उनके द्वारा प्रणाली के बारे में बनाए गए मानसिक मॉडल के अनुरूप हो।
इस चरण के दौरान लटकते हुए प्रवाहों की तलाश करें। ये वे तीर हैं जो कहीं भी नहीं जाते। प्रत्येक प्रवाह को किसी प्रक्रिया, स्टोर या एकाधिकारी से जोड़ा जाना चाहिए। साथ ही, प्रतिच्छेदन वाली रेखाओं की जांच करें। यह सख्ती से निषिद्ध नहीं है, लेकिन प्रतिच्छेदन वाली रेखाएं आरेख को पढ़ने में कठिन बना सकती हैं। प्रतिच्छेदन से बचने के लिए रेखाओं के मार्ग को बदलने की कोशिश करें।
समीक्षा का एक अन्य पहलू नामकरण प्रणाली है। सुनिश्चित करें कि आरेख के सभी हिस्सों में एक ही डेटा का एक ही नाम से संदर्भित किया जाए। यदि आप एक भाग में इसे “ग्राहक आईडी” कहते हैं, तो दूसरे भाग में इसे “ग्राहक संख्या” नहीं कहें। सुसंगतता समझ में मदद करती है।
समय के साथ रखरखाव 🛠️
एक डीएफडी एक बार के लिए बनाया गया तत्व नहीं है। प्रणालियाँ विकसित होती हैं। आवश्यकताएँ बदलती हैं। जैसे ही प्रणाली बदलती है, आरेख को नई वास्तविकता को दर्शाने के लिए अद्यतन किया जाना चाहिए। एक जमा हुआ आरेख, बिना किसी आरेख के भी बदतर है, क्योंकि यह विकासकर्ताओं और विश्लेषकों को भ्रमित करता है।
अपने आरेखों के लिए एक संस्करण प्रणाली स्थापित करें। जब कोई महत्वपूर्ण परिवर्तन होता है, तो संस्करण संख्या को अद्यतन करें। इससे प्रणाली डिज़ाइन के इतिहास को ट्रैक करने में मदद मिलती है। इसके अलावा नए सदस्यों को यह समझने में सहायता मिलती है कि प्रणाली कैसे विकसित हुई है।
प्रणाली विश्लेषण के साथ एकीकरण 📋
डीएफडी का अक्सर अकेले उपयोग नहीं किया जाता है। ये एक बड़े दस्तावेज़ संग्रह का हिस्सा होते हैं। इनके साथ डेटा शब्दकोश और प्रक्रिया विवरण अक्सर आते हैं। एक डेटा शब्दकोश आरेख में पाए जाने वाले डेटा तत्वों के गुणों को परिभाषित करता है। एक प्रक्रिया विवरण एक विशिष्ट प्रक्रिया बबल के भीतर के तर्क को विस्तार से बताता है।
इन दस्तावेज़ों को जोड़कर आप एक व्यापक विवरण बनाते हैं। यह दस्तावेज़ विकास टीम को प्रणाली बनाने में सहायता करता है। यह सुनिश्चित करता है कि अंतिम उत्पाद प्रारंभिक विश्लेषण के अनुरूप हो।
आरेखण अभ्यास पर निष्कर्ष
डेटा प्रवाह आरेख बनाना संचार का एक अनुशासित अभ्यास है। यह अमूर्त आवश्यकताओं को एक दृश्य रूप में बदलता है जो समझने में आसान होता है। मानक घटकों, नोटेशन शैलियों और संतुलन नियमों का पालन करके, आप सुनिश्चित करते हैं कि आरेख अपने उद्देश्य को प्रभावी ढंग से पूरा करे।
याद रखें कि लक्ष्य स्पष्टता है। यदि कोई हितधारक आरेख को देखता है और प्रणाली को समझ जाता है, तो आरेख सफल हुआ है। यदि आरेख को समझने के लिए विरोधाभासी व्याख्या की आवश्यकता होती है, तो आरेख को संशोधित करने की आवश्यकता होती है। सूचना के प्रवाह पर ध्यान केंद्रित करें, नोटेशन में स्थिरता बनाए रखें, और क्षेत्र को स्पष्ट रखें। अभ्यास के साथ, सटीक और उपयोगी डेटा प्रवाह आरेख बनाना प्रणाली डिज़ाइन प्रक्रिया का एक प्राकृतिक हिस्सा बन जाता है।