











एक प्रणाली के माध्यम से जानकारी के आवागमन को समझना प्रणाली विश्लेषण और डिजाइन के लिए मूलभूत है। डेटा फ्लो डायग्राम (DFD) इस आवागमन का दृश्य प्रतिनिधित्व प्रदान करता है। कोड या डेटाबेस स्कीमा पर ध्यान केंद्रित तकनीकी ब्लूप्रिंट्स के विपरीत, एक DFD डेटा के प्रवाह और उसे बदलने वाली प्रक्रियाओं पर ध्यान केंद्रित करता है। इस मार्गदर्शिका में इन आरेखों को बनाने के लिए उपयोग किए जाने वाले महत्वपूर्ण प्रतीकों का विवरण दिया गया है, जिससे आपके दस्तावेजीकरण में स्पष्टता और सटीकता सुनिश्चित होती है।
डेटा फ्लो डायग्राम क्या है? 🤔
एक डेटा फ्लो डायग्राम एक संरचित विश्लेषण उपकरण है। यह जानकारी प्रसंस्करण गतिविधियों के क्रम को नक्शा बनाता है। यह प्रणाली के तर्क को प्रोग्रामिंग कोड के संदर्भ में नहीं बताता है। इसके बजाय, यह यह दर्शाता है कि कौन सी डेटा ले जाई जाती है, यह कहाँ से आती है, कहाँ जाती है, और यह कैसे बदलती है। इस अमूल्य अवधारणा के कारण स्टेकहोल्डर्स को तकनीकी कार्यान्वयन विवरणों में फंसे बिना कार्यात्मक आवश्यकताओं को समझने में सक्षम होते हैं।
DFD हीरार्किक होते हैं। वे एक उच्च-स्तरीय समीक्षा के साथ शुरू होते हैं और क्रमशः अधिक विस्तृत दृश्यों में विभाजित होते हैं। इस विभाजन से जटिलता का प्रबंधन करने में मदद मिलती है। सीमाओं और बातचीत को परिभाषित करके, विश्लेषक विकास शुरू होने से पहले आवश्यकताओं में अंतराल या संभावित बाधाओं की पहचान कर सकते हैं।
चार मुख्य प्रतीक 🛠️
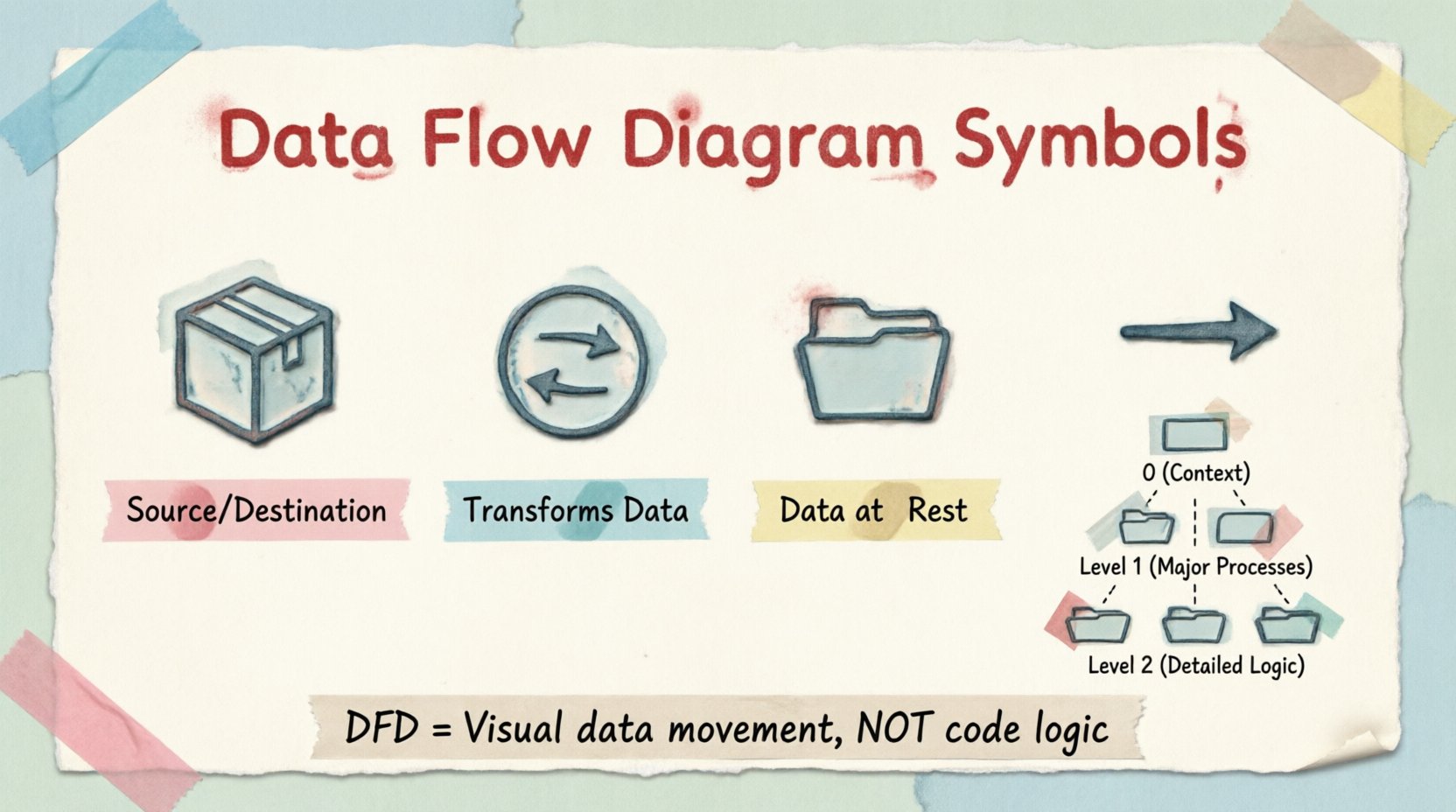
मानक DFD नोटेशन चार प्राथमिक आकृतियों पर निर्भर करता है। भिन्न-भिन्न विधियों (जैसे यौरडॉन/डेमार्को या गेने/सर्सन) के बीच भिन्नताएँ हो सकती हैं, लेकिन मूल अवधारणाएँ संगत रहती हैं। प्रत्येक प्रतीक प्रणाली सीमा के भीतर एक विशिष्ट कार्य का प्रतिनिधित्व करता है।
| प्रतीक का नाम | दृश्य प्रतिनिधित्व | कार्य |
|---|---|---|
| बाहरी एकाधिकार | आयत | डेटा का स्रोत या गंतव्य |
| प्रक्रिया | वृत्त या गोल आयत | डेटा का परिवर्तन |
| डेटा भंडार | खुला आयत | विश्राम में डेटा का भंडारण |
| डेटा प्रवाह | तीर | डेटा का आवागमन |
1. बाहरी एकाधिकार 📦
बाहरी एकाधिकार उन डेटा स्रोतों या गंतव्यों का प्रतिनिधित्व करते हैं जो मॉडल की जा रही प्रणाली के बाहर हैं। वे ऐसे क्रियाकलापकर्ता हैं जो प्रणाली से बातचीत करते हैं लेकिन इसकी आंतरिक तर्क का हिस्सा नहीं हैं। एक एकाधिकार एक व्यक्ति, एक समूह, एक अन्य कंप्यूटर प्रणाली या एक विभाग हो सकता है।
एकाधिकार को आमतौर पर आयत के रूप में बनाया जाता है। कुछ नोटेशन में इन्हें अंडाकार आकृति के रूप में दिखाया जा सकता है। मुख्य विशेषता यह है कि प्रणाली उन्हें डेटा भेजती है या उनसे डेटा प्राप्त करती है। उदाहरण के लिए, एक ग्राहक एक एकाधिकार है। प्रणाली उनके आदेश को प्रसंस्कृत करती है, लेकिन ग्राहक आदेश प्रसंस्करण सॉफ्टवेयर से स्वतंत्र रूप से अस्तित्व में है।
- प्रवेश: डेटा एकाधिकार से प्रणाली में प्रवेश करता है।
- आउटपुट: डेटा प्रणाली से बाहर निकलता है और एकाधिकार की ओर जाता है।
बाहरी एकाधिकार और प्रक्रियाओं के बीच भ्रम नहीं होना चाहिए। एक एकाधिकार डेटा को नहीं बदलता है; वह बस इसका उत्पादन करता है या इसका उपभोग करता है।
2. प्रक्रिया 🔄
प्रक्रियाएँ आरेख के सक्रिय तत्व हैं। वे इनपुट डेटा को आउटपुट डेटा में बदलने वाले कार्यों का प्रतिनिधित्व करती हैं। एक प्रक्रिया कार्य कर रही है। यह एक गणना, एक प्रमाणीकरण जांच, एक निर्णय या डेटा संशोधन रूटीन हो सकती है।
प्रक्रियाओं को आमतौर पर वृत्त या गोल आयत के रूप में बनाया जाता है। आकृति के भीतर आप कार्य का वर्णन करने वाला नाम रखते हैं, जैसे “कुल गणना” या “लॉगिन की पुष्टि करें”। प्रत्येक प्रक्रिया के कम से कम एक इनपुट और कम से कम एक आउटपुट होना चाहिए। यदि कोई प्रक्रिया डेटा के आने के लिए है लेकिन आउटपुट के लिए कुछ नहीं है, तो वह अपूर्ण है।
प्रक्रियाओं को श्रेणीबद्धता को दर्शाने के लिए नंबर दिए जाते हैं। उदाहरण के लिए, “प्रक्रिया 1” को “प्रक्रिया 1.1”, “प्रक्रिया 1.2” आदि में विभाजित किया जा सकता है। इस नंबरिंग से विभिन्न आरेखों में विवरण स्तरों को ट्रैक करने में मदद मिलती है।
3. डेटा स्टोर 📁
डेटा स्टोर वह स्थान हैं जहां डेटा भविष्य के उपयोग के लिए संग्रहीत किया जाता है। वे भंडार हैं। एक भौतिक प्रणाली में, यह एक डेटाबेस टेबल, एक फ़ाइल या एक भौतिक फ़ाइलिंग कैबिनेट हो सकता है। एक तार्किक आरेख में, यह सिर्फ वह स्थान है जहां डेटा रुकता है।
आम आकृतियां खुले आयताकार या समानांतर रेखाएं होती हैं। स्टोर के अंदर का नाम बहुवचन में होना चाहिए, जो रिकॉर्ड के संग्रह को इंगित करता है, जैसे कि “ग्राहक फ़ाइलें” या “आदेश लॉग”।
- पढ़ें: एक प्रक्रिया डेटा को उपयोग करने के लिए स्टोर से डेटा पढ़ती है।
- लिखें: एक प्रक्रिया डेटा को संग्रहीत करने के लिए स्टोर में डेटा लिखती है।
डेटा स्टोर में आता और बाहर निकलता है। यह ध्यान देने योग्य है कि डेटा प्रवाह किसी प्रक्रिया के माध्यम से न गुजरे बिना एक दूसरे को नहीं पार कर सकते। आप दो डेटा स्टोर के बीच सीधी रेखा नहीं खींच सकते; डेटा के आगे बढ़ने के कारण को परिभाषित करने के लिए एक प्रक्रिया के बीच में होना चाहिए।
4. डेटा प्रवाह ➡️
डेटा प्रवाह प्रतीकों को जोड़ने वाली तीर हैं। वे प्रणाली के माध्यम से डेटा के गति का प्रतिनिधित्व करते हैं। प्रोग्रामिंग में नियंत्रण प्रवाह के विपरीत, डेटा प्रवाह वास्तविक सूचना पैकेट का प्रतिनिधित्व करता है।
प्रत्येक तीर को उस डेटा के नाम से लेबल किया जाना चाहिए जो उसके माध्यम से गति कर रहा है। उदाहरण के लिए, एक ग्राहक से एक प्रक्रिया तक जाने वाली तीर को “आदेश अनुरोध” के रूप में लेबल किया जा सकता है। एक प्रक्रिया से डेटा स्टोर तक जाने वाली तीर को “नया आदेश रिकॉर्ड” के रूप में लेबल किया जा सकता है।
तीरों की दिशा एक ही होनी चाहिए। यदि दो बिंदुओं के बीच डेटा दोनों दिशाओं में गति करता है, तो दो अलग-अलग तीरों का उपयोग करें। लेबल को एक ही वचन (एकवचन या बहुवचन) में रखें। “डेटा” या “सूचना” जैसे अस्पष्ट लेबल से बचें। विशिष्ट हों, जैसे “शिपिंग पता” या “इन्वेंटरी रिपोर्ट”।
DFD स्तरों को समझना 📈
DFD को जटिलता को प्रबंधित करने के लिए परतों में बनाया जाता है। इस दृष्टिकोण को विघटन कहा जाता है।
स्तर 0: संदर्भ आरेख
स्तर 0 का आरेख सबसे ऊंचा स्तर है। यह पूरी प्रणाली को एकल प्रक्रिया के रूप में दिखाता है। यह प्रणाली और बाहरी एकाधिकारों के बीच संबंध को उजागर करता है। इस दृष्टिकोण का उत्तर है: “प्रणाली की सीमा क्या है?”
इस आरेख में केवल एक प्रक्रिया नोड होता है। सभी डेटा प्रवाह बाहरी एकाधिकारों को इस केंद्रीय प्रक्रिया से सीधे जोड़ते हैं। इस स्तर पर आंतरिक डेटा स्टोर नहीं दिखाए जाते हैं, क्योंकि आंतरिक कार्यप्रणाली छुपाई जाती है।
स्तर 1: मुख्य प्रक्रियाएं
स्तर 1 का आरेख स्तर 0 से एकल प्रक्रिया को उसके मुख्य उप-प्रक्रियाओं में विस्फोट करता है। यह प्रणाली को प्रबंधन योग्य टुकड़ों में बांटता है। आपको बहुत सारे प्रक्रिया नोड, डेटा स्टोर और उन्हें जोड़ने वाले विशिष्ट प्रवाह दिखाई देंगे।
इस स्तर पर मुख्य कार्यात्मक क्षेत्रों को परिभाषित किया जाता है। उदाहरण के लिए, ई-कॉमर्स प्रणाली को “इन्वेंटरी प्रबंधन”, “भुगतान प्रक्रिया” और “शिपिंग प्रबंधन” में विभाजित किया जा सकता है। इनमें से प्रत्येक एक प्रमुख प्रक्रिया का प्रतिनिधित्व करता है।
स्तर 2: विस्तृत तर्क
स्तर 2 के आरेख स्तर 1 की विशिष्ट प्रक्रियाओं में गहराई से जाते हैं। यदि स्तर 1 की प्रक्रिया जटिल है, तो उसका अपना आरेख होता है। इससे विश्लेषकों को किसी विशिष्ट कार्य के हर चरण को नक्शा बनाने में सहायता मिलती है बिना समग्र दृश्य को भ्रमित किए।
इस चरण पर, नोटेशन अधिक विस्तृत हो जाता है। आपको बहुत सारे डेटा स्टोर और डेटा प्रवाह के जटिल मार्गदर्शन दिखाई दे सकते हैं। यहीं विशिष्ट व्यावसायिक नियमों को आमतौर पर दृश्याकृत किया जाता है।
नियम और प्रथाएं ✅
स्पष्टता बनाए रखने के लिए, DFD को सख्त नियमों का पालन करना चाहिए। इन नियमों के उल्लंघन से भ्रम और गलत व्याख्या हो सकती है।
नामकरण में सामंजस्य
एक ही डेटा प्रवाह को हर जगह एक ही नाम देना चाहिए। यदि आप एक आरेख पर प्रवाह को “उपयोगकर्ता ID” के रूप में लेबल करते हैं, तो दूसरे आरेख पर इसे “ID संख्या” नहीं कहा जा सकता है। सामंजस्य डेटा के स्तरों के माध्यम से ट्रेस करने में मदद करता है।
कोई काले छेद या चमत्कार नहीं
एक “काला छेद” वह प्रक्रिया है जिसमें इनपुट है लेकिन आउटपुट नहीं है। इसका अर्थ है कि डेटा गायब हो जाता है, जो आमतौर पर गलत होता है। एक “चमत्कार” वह प्रक्रिया है जिसमें आउटपुट है लेकिन इनपुट नहीं है। इसका अर्थ है कि डेटा कहीं से आ गया है। दोनों आरेख में तार्किक त्रुटियां हैं।
डेटा स्टोर संतुलन
जब आप एक प्रक्रिया को विघटित करते हैं, तो मूल प्रक्रिया से जुड़े डेटा स्टोर को बच्चे की प्रक्रियाओं से जुड़े रहना चाहिए। आप किसी निचले स्तर पर डेटा स्टोर को हटा नहीं सकते जब तक कि तर्क में महत्वपूर्ण परिवर्तन नहीं होता। डेटा के प्रवाह को स्तरों के बीच संतुलित रखना चाहिए।
तीर की दिशा
तीर दिशा को इंगित करते हैं। बेवजह तीरों को एक दूसरे को काटने वाले नहीं बनाएं। प्रतिच्छेदन वाली रेखाएं आरेख को पढ़ने में कठिन बना देती हैं। मार्ग स्पष्ट रखने के लिए वक्र या तोड़ का उपयोग करें। यदि दो प्रवाह एक दूसरे को काटते हैं, तो सुनिश्चित करें कि डेटा प्रकार अलग-अलग हों ताकि भ्रम न हो।
DFD बनाम फ्लोचार्ट 🧩
डेटा प्रवाह आरेखों को फ्लोचार्ट से भ्रमित करना आम बात है। जबकि वे दिखने में समान हैं, लेकिन उनके उद्देश्य अलग-अलग होते हैं।
एक फ्लोचार्ट संचालन के तर्क और क्रम का वर्णन करता है। यह निर्णय बिंदु (हीरे), लूप और चरणों के सटीक क्रम को दिखाता है। यह प्रक्रियात्मक है। यह “प्रणाली कैसे कार्यान्वित होती है?” का उत्तर देता है।
एक DFD डेटा के गति का वर्णन करता है। यह लूप या निर्णय तर्क को स्पष्ट रूप से नहीं दिखाता है। यह डेटा के “क्या” और “कहां” पर ध्यान केंद्रित करता है। यह “कौन सा डेटा आगे बढ़ाया जाता है और परिवर्तित किया जाता है?” का उत्तर देता है।
नियंत्रण तर्क के लिए DFD का उपयोग करना एक गलती है। इसमें निर्णय हीरे नहीं होने चाहिए। यदि आप तर्क दिखाना चाहते हैं, तो DFD के साथ निर्णय तालिका या संरचित अंग्रेजी विवरण का उपयोग करें। इस चिंता के विभाजन से आरेख साफ रहता है।
व्यावहारिक अनुप्रयोग 📝
आरेख बनाते समय, संदर्भ आरेख से शुरुआत करें। प्रणाली की सीमा को पहचानें। बाहरी एकाधिकारों को खींचें। प्रणाली का प्रतिनिधित्व करने वाली एकल प्रक्रिया को खींचें। उन्हें जोड़ने वाले प्रवाहों को खींचें।
अगले, स्तर 1 पर जाएं। केंद्रीय प्रक्रिया को मुख्य कार्यों में बांटें। डेटा कहां संग्रहीत होता है, इसकी पहचान करें। सुनिश्चित करें कि प्रत्येक प्रक्रिया के इनपुट और आउटपुट हैं। जांचें कि प्रवाह संदर्भ आरेख के अनुरूप हैं।
हितधारकों के साथ आरेख की समीक्षा करें। पूछें कि क्या प्रवाह व्यवसाय की समझ के अनुरूप हैं। यदि कोई हितधारक कहता है, “हम वह डेटा यहां संग्रहीत नहीं करते हैं,” तो डेटा स्टोर को समायोजित करें। यदि वे कहते हैं, “हम उस व्यक्ति को डेटा नहीं भेजते हैं,” तो एकाधिकारों को समायोजित करें।
सत्यापन महत्वपूर्ण है। उपयोगकर्ताओं द्वारा समझे जाने वाले आरेख के बिना आरेख बेकार है। यह संचार उपकरण के रूप में कार्य करता है। यह तकनीकी टीमों और व्यवसाय मालिकों के बीच के अंतर को पार करता है।
स्पष्टता के लिए सर्वोत्तम प्रथाएं 🌟
एक पृष्ठ पर प्रतीकों की संख्या को नियंत्रित रखें। यदि आरेख बहुत भीड़ जैसा हो जाता है, तो उसका मूल्य खो जाता है। इसे तोड़ने के लिए उप-आरेखों का उपयोग करें। यदि दृश्य क्षमता से अधिक है, तो एक ही पृष्ठ पर पूरी प्रणाली को दिखाने की कोशिश न करें।
मानक नोटेशन का उपयोग करें। हालांकि विभिन्न प्रकार हैं, लेकिन एक शैली (जैसे यूरडॉन/डेमार्को या गेने/सर्सन) का पालन करने से भ्रम बचता है। एक ही दस्तावेज में शैलियों को मिलाने की कोशिश न करें।
सब कुछ को लेबल करें। बिना लेबल के तीर अर्थहीन हैं। बिना लेबल की प्रक्रियाएं अस्पष्ट हैं। यहां तक कि सरल आकृतियों को अर्थ प्रदान करने के लिए नाम की आवश्यकता होती है।
प्रतिच्छेदन वाली रेखाओं से बचें। यह दृश्य शोर में बदल जाता है। यदि रेखाएं जरूरी हैं तो उनके प्रतिच्छेदन को दर्शाने के लिए “जंप” या रेखा में तोड़ का उपयोग करें।
प्रतीक अर्थविज्ञान का सारांश 📋
मुख्य घटकों का पुनरावलोकन करने के लिए:
- एकाधिकार: प्रणाली के बाहर। स्रोत या निकास।
- प्रक्रिया: प्रणाली के भीतर। डेटा को परिवर्तित करता है।
- स्टोर: प्रणाली के भीतर। डेटा को संग्रहीत करता है।
- प्रवाह: उपरोक्त को जोड़ता है। डेटा को ले जाता है।
इन प्रतीकों को समझने से आप जटिल प्रणालियों को स्पष्ट रूप से दस्तावेज़ कर सकते हैं। यह विश्लेषकों और विकासकर्मियों के लिए एक साझा भाषा प्रदान करता है। विभाजन और सुसंगतता के नियमों का पालन करके, आप आरेख बनाते हैं जो केवल चित्र नहीं हैं, बल्कि कार्यात्मक विवरण हैं।
सरल शुरुआत करें। संदर्भ बनाएं। विवरण बढ़ाएं। उपयोगकर्ताओं के साथ सत्यापित करें। यह आवर्ती प्रक्रिया सुनिश्चित करती है कि आरेख वास्तविकता का प्रतिनिधित्व करता है।