











एक प्रणाली में जानकारी कैसे यात्रा करती है, इसकी समझ भरोसेमंद सॉफ्टवेयर आर्किटेक्चर बनाने के लिए मूलभूत है। जब हम डेटा फ्लो डायग्राम (DFD) का उपयोग करके एक प्रणाली को मानचित्रित करते हैं, तो हम सिर्फ बॉक्स और रेखाएं बना रहे हैं; हम डेटा के जीवनचक्र को चार्ट कर रहे हैं। डेटा गतिशीलता मार्गों का विश्लेषण करने के लिए डेटा के उत्पत्ति स्थान, उसके परिवर्तन के तरीके, उसके आराम के स्थान और पर्यावरण से बाहर निकलने के तरीके का कठोर विश्लेषण करना आवश्यक है। इस प्रक्रिया से पूरी आर्किटेक्चर में अखंडता, प्रदर्शन और सुरक्षा सुनिश्चित होती है।
स्पष्ट मानचित्र के बिना, डेटा खो जा सकती है, दोहराई जा सकती है या अनधिकृत पहुंच के लिए खुली रह सकती है। एक विस्तृत विश्लेषण बॉटलनेक, छिपे हुए निर्भरताओं और संभावित विफलता के बिंदुओं को उत्पादन के प्रभाव के पहले उजागर करता है। यह गाइड इन मार्गों को सटीकता और स्पष्टता के साथ विश्लेषित करने की विधि का अध्ययन करता है।
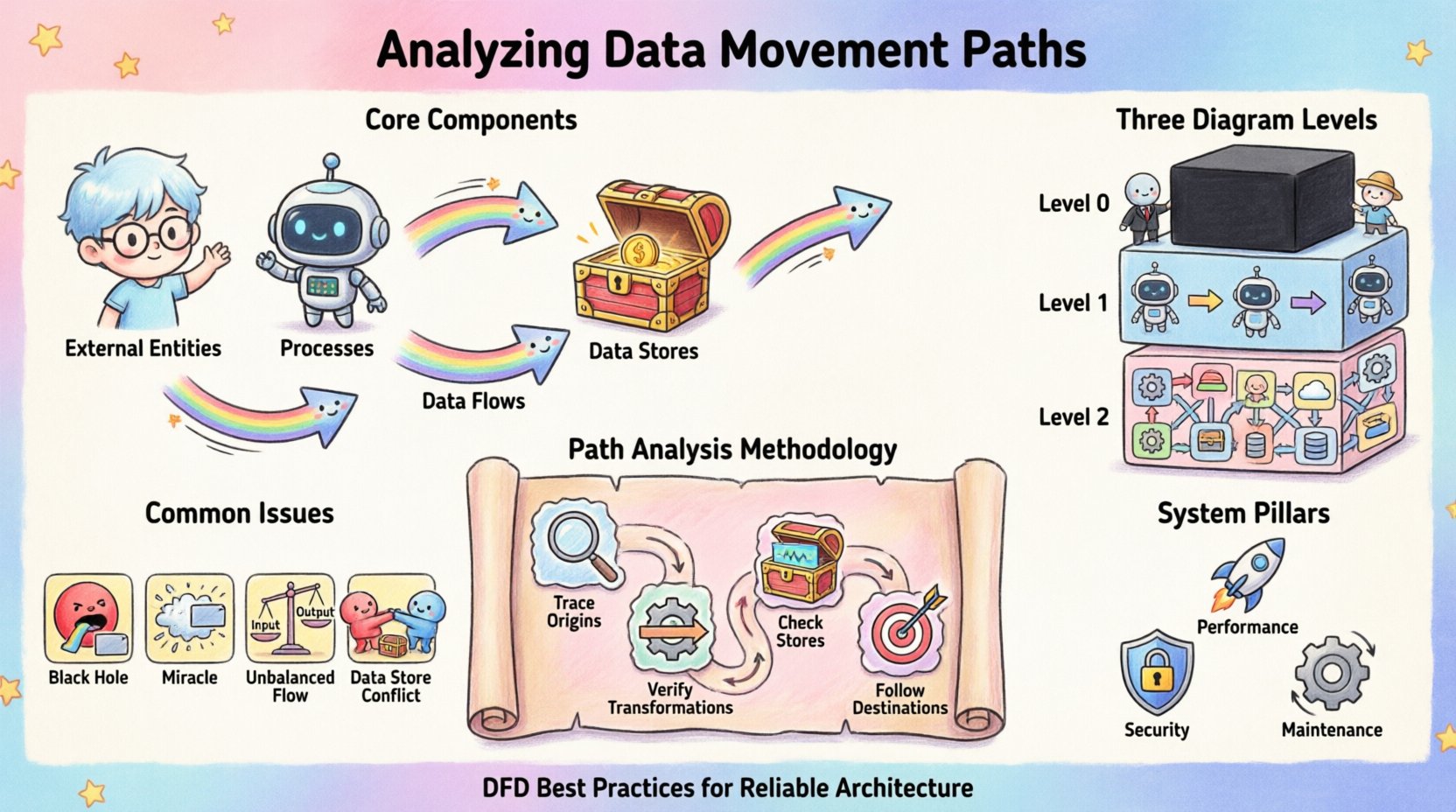
डेटा गतिशीलता के मुख्य घटक 🧩
गतिशीलता का प्रभावी विश्लेषण करने के लिए, पहले उन अलग-अलग तत्वों को पहचानना आवश्यक है जो इसे संभव बनाते हैं। प्रत्येक DFD धाराओं का वर्णन करने के लिए एक स्थिर शब्दावली पर निर्भर करता है। इन परिभाषाओं को नजरअंदाज करने से मॉडल में अस्पष्टता आती है।
- बाहरी एजेंसियाँ: ये प्रणाली की सीमा के बाहर के स्रोत या गंतव्य का प्रतिनिधित्व करते हैं। वे डेटा के अनुरोध शुरू करते हैं या प्रसंस्कृत आउटपुट प्राप्त करते हैं। उदाहरण में मानव उपयोगकर्ता, अन्य प्रणालियाँ या तृतीय-पक्ष सेवाएं शामिल हैं।
- प्रक्रियाएँ: ये परिवर्तन हैं। एक प्रक्रिया इनपुट डेटा लेती है, तर्क या नियमों को लागू करती है और आउटपुट उत्पन्न करती है। यह प्रणाली के भीतर परिवर्तन का इंजन है।
- डेटा स्टोर: ये भंडार हैं जहाँ जानकारी बाद में प्राप्त करने के लिए रखी जाती है। वे स्थायित्व प्रदान करते हैं, जिससे डेटा प्रक्रिया के तुरंत कार्यान्वयन के बाद भी बना रह सकती है।
- डेटा प्रवाह: ये घटकों को जोड़ने वाली तीर हैं। वे एजेंसियों, प्रक्रियाओं और स्टोर के बीच डेटा पैकेट या रिकॉर्ड के वास्तविक गतिशीलता का प्रतिनिधित्व करते हैं।
प्रत्येक तीर को एक वर्णनात्मक लेबल होना चाहिए जो स्पष्ट रूप से बताए कि कौन सी जानकारी यात्रा कर रही है। “जानकारी” या “डेटा” जैसे अस्पष्ट लेबल ट्रांसफर की विशिष्ट प्रकृति को छिपा देते हैं, जिससे विश्लेषण कठिन हो जाता है।
चित्रण में विवरण के स्तर 📊
डेटा गतिशीलता अक्सर स्थिर नहीं होती; यह विभिन्न स्तरों के सारांश में मौजूद होती है। एक ही आरेख हर बाइट जानकारी को नहीं दर्शा सकता। इसके बजाय, हम प्रणाली को विभाजित करने के लिए एक पदानुक्रमिक दृष्टिकोण का उपयोग करते हैं।
1. संदर्भ आरेख (स्तर 0)
उच्चतम स्तर का दृश्य पूरी प्रणाली को एकल काले बॉक्स के रूप में लेता है। यह प्रणाली के बाहरी एजेंसियों के साथ बातचीत करते हुए दिखाता है। यह सीमाओं को समझने के लिए निर्णायक है। यह प्रश्न का उत्तर देता है: प्रणाली बाहरी दुनिया के साथ क्या बदलती है?
2. स्तर 1 आरेख
यहाँ, काला बॉक्स प्रमुख प्रक्रियाओं में फूट जाता है। इस स्तर पर प्राथमिक उप-प्रणालियाँ और उच्च स्तर के डेटा के बीच गतिशीलता कैसे होती है, इसका पता चलता है। यह छोटी-छोटी तर्क के बीच फंसे बिना आंतरिक आर्किटेक्चर का मैक्रो दृश्य प्रदान करता है।
3. स्तर 2 आरेख और नीचे
जटिल प्रक्रियाओं के लिए आगे का विभाजन होता है। इन विस्तृत दृश्यों में विशिष्ट परिवर्तन और डेटा की बारीक गतिशीलता दिखाई जाती है। इस स्तर को विशिष्ट सत्यापन चरणों और त्रुटि प्रबंधन तंत्रों की पहचान करने के लिए आवश्यक है।
जब मार्गों का विश्लेषण करते हैं, तो स्तरों के बीच संगतता महत्वपूर्ण है। स्तर 1 प्रक्रिया में प्रवेश करने वाले डेटा को उसके बाहर निकलने वाले डेटा से मेल खाना चाहिए। स्तरों के बीच अंतर डिजाइन में खामियों को दर्शाते हैं।
मार्ग विश्लेषण की विधि 🔍
डेटा मार्ग का अनुसरण करना एक व्यवस्थित अभ्यास है। इसमें स्रोत से सिंक तक निशान लगाना शामिल है। इस प्रक्रिया में तर्कसंगत त्रुटियों और गायब संयोजनों की पहचान करने में मदद मिलती है।
चरण 1: इनपुट के स्रोत का अनुसरण करें
एक बाहरी एजेंसी से शुरू करें। तीर के अनुसार प्रणाली में प्रवेश करें। अगले चरण में यह डेटा कहाँ जाता है, इसके बारे में पूछें। क्या यह प्रक्रिया या स्टोर में जाता है? यदि यह प्रक्रिया में जाता है, तो क्या उस प्रक्रिया के पास कार्य करने के लिए पर्याप्त जानकारी है? प्रत्येक प्रक्रिया के कम से कम एक इनपुट और एक आउटपुट होना चाहिए।
चरण 2: परिवर्तनों की पुष्टि करें
जब डेटा एक प्रक्रिया में प्रवेश करता है, तो परिवर्तन का विश्लेषण करें। क्या आउटपुट इनपुट से तार्किक रूप से निकला है? कभी-कभी, एक प्रक्रिया के आउटपुट में वह डेटा दिखाई देता है जो इनपुट में नहीं था। इसे एक “चमत्कार” कहा जाता है और इसका अर्थ है कि इनपुट की कमी है या कोड में निर्धारित स्थिर मान है जिसे दस्तावेज़ में दर्ज करना चाहिए।
चरण 3: डेटा स्टोर की जाँच करें
प्रत्येक पढ़ने और लिखने के ऑपरेशन की पहचान करें। एक डेटा स्टोर एक मृत अंत नहीं होना चाहिए। यदि डेटा एक स्टोर में प्रवेश करता है, तो किसी बिंदु पर उसके बाहर निकलने का प्रवाह होना चाहिए, अन्यथा यदि डेटा स्थायी रूप से संग्रहीत कर दी गई है। सुनिश्चित करें कि आरेख द्वारा निर्दिष्ट स्कीमा भौतिक स्टोरेज की आवश्यकताओं के अनुरूप है।
चरण 4: आउटपुट गंतव्यों का अनुसरण करें
प्रोसेस की गई डेटा कहाँ जाती है? क्या यह उपयोगकर्ता के पास वापस आती है? क्या यह एक अन्य प्रक्रिया को ट्रिगर करती है? क्या यह सिस्टम सीमा से बाहर निकलती है? सुनिश्चित करें कि प्रत्येक आउटपुट पथ का ध्यान रखा गया है। कोई भी गंतव्य नहीं वाली डेटा उत्पन्न करने वाली असंगत प्रक्रियाएँ अपूर्ण डिजाइन का संकेत हैं।
सामान्य संरचनात्मक समस्याएँ ⚠️
विश्लेषण के दौरान, डिजाइन की कमियों को दर्शाने वाले विशिष्ट पैटर्न उभरते हैं। इन्हें जल्दी पहचानने से बाद में महंगे रीफैक्टरिंग से बचा जा सकता है।
| समस्या | विवरण | प्रभाव |
|---|---|---|
| काला छेद | एक प्रक्रिया के इनपुट हैं लेकिन आउटपुट नहीं हैं। | डेटा का उपयोग किया जाता है और गायब हो जाता है। तर्क अपूर्ण है। |
| चमत्कार | एक प्रक्रिया के आउटपुट हैं लेकिन इनपुट नहीं हैं। | डेटा बिना कारण दिखाई देती है। तर्क अपरिभाषित है। |
| असंतुलित प्रवाह | इनपुट और आउटपुट डेटा स्तरों के बीच मेल नहीं खाते हैं। | विघटन के दौरान डेटा अखंडता का नुकसान। |
| डेटा स्टोर संघर्ष | एक ही स्टोर में बहुत सी प्रक्रियाएँ लॉक किए बिना लिखती हैं। | समानांतरता की समस्याएँ और डेटा क्षति। |
सुरक्षा और सुसंगतता के मामले 🔒
सुरक्षा एक अतिरिक्त चीज नहीं है; यह डेटा गतिशीलता की एक विशेषता है। मार्गों के विश्लेषण से हम यह पहचान सकते हैं कि संवेदनशील जानकारी कहाँ रहती है और कहाँ यात्रा करती है।
संवेदनशील डेटा की पहचान करना
व्यक्तिगत रूप से पहचान योग्य जानकारी (PII) या वित्तीय रिकॉर्ड का पता लगाएं। यदि संवेदनशील डेटा प्रक्रियाओं के बीच गतिशील होती है, तो क्या इसके एन्क्रिप्शन की आवश्यकता है? यदि यह किसी स्टोर में रुकती है, तो क्या पहुँच नियंत्रित है? आरेख में इन संवेदनशील प्रवाहों को उजागर करना चाहिए, शायद अलग लाइन शैलियों या लेबल का उपयोग करके।
पहुँच नियंत्रण बिंदु
प्रत्येक प्रक्रिया एक संभावित गेटकीपर के रूप में कार्य करती है। प्रत्येक प्रक्रिया के लिए प्रमाणीकरण की आवश्यकता का विश्लेषण करें। क्या डेटा प्रवाह आरेख यह संकेत देता है कि कोई भी प्रक्रिया किसी भी स्टोर तक पहुँच सकती है? यह अक्सर सख्त भूमिका-आधारित पहुँच नियंत्रण की आवश्यकता को इंगित करता है।
नियामक सुसंगतता
नियमों के अनुसार डेटा कहाँ रह सकती है, इसका निर्धारण किया जाता है। उदाहरण के लिए, कुछ विधायी क्षेत्रों में डेटा को विशिष्ट भौगोलिक सीमाओं के भीतर रहने की आवश्यकता होती है। ऐसे डेटा गतिशीलता मार्ग जो इन सीमाओं को पार करते हैं, को कानूनी समीक्षा के लिए चिह्नित करना चाहिए। आरेख सुसंगतता आर्किटेक्चर के सबूत के रूप में कार्य करता है।
प्रदर्शन और अनुकूलन 🚀
डेटा गतिशीलता मुफ्त नहीं है। यह बैंडविड्थ, प्रोसेसिंग पावर और समय का उपयोग करती है। मार्गों के विश्लेषण से इन संसाधनों को अनुकूलित करने में मदद मिलती है।
बॉटलनेक की पहचान करना
बहुत अधिक उच्च आयतन वाले इनपुट और आउटपुट वाली प्रक्रियाओं की तलाश करें। इन्हें प्रदर्शन बॉटलनेक के रूप में बनने की संभावना है। यदि एक ही प्रक्रिया पांच अलग-अलग स्रोतों से डेटा एकत्र करती है और फिर उसे आगे भेजती है, तो यह लोड के तहत कठिनाई महसूस कर सकती है। इसे समानांतर प्रक्रियाओं में विभाजित करने के बारे में सोचें।
प्रतिक्रिया समय विश्लेषण
डेटा के अपने गंतव्य तक पहुंचने के लिए लिए जाने वाले हॉप्स की संख्या का गणना करें। प्रत्येक हॉप प्रतिक्रिया समय जोड़ता है। यदि एक उपयोगकर्ता अनुरोध को परिणाम लौटाए जाने से पहले दस प्रक्रियाओं से गुजरना हो, तो प्रणाली धीमी महसूस होगी। परिवर्तनों की संख्या को कम करने से प्रतिक्रियाशीलता में सुधार हो सकता है।
आवर्धन कम करना
डुप्लीकेट डेटा प्रवाह की जांच करें। यदि एक ही जानकारी तीन अलग-अलग प्रक्रियाओं को भेजी जाती है, तो विचार करें कि क्या उन्हें एक सामान्य डेटा स्टोर साझा करने की आवश्यकता है। इससे नेटवर्क ट्रैफिक कम होता है और सुसंगतता सुनिश्चित होती है।
चित्र की सटीकता बनाए रखना 🔄
एक चित्र एक जीवित दस्तावेज है। जैसे-जैसे प्रणाली विकसित होती है, मार्ग बदलते हैं। सटीकता बनाए रखने के लिए एक अनुशासित दृष्टिकोण की आवश्यकता होती है।
संस्करण नियंत्रण
डेटा प्रवाह संरचना में किए गए हर बदलाव को संस्करण बनाया जाना चाहिए। इससे टीमों को यह ट्रेस करने में मदद मिलती है कि किसी विशिष्ट मार्ग में कब बदलाव किया गया। यह डिबगिंग और प्रभाव विश्लेषण के लिए आवश्यक है।
प्रभाव विश्लेषण
किसी प्रक्रिया को संशोधित करने से पहले, सभी जुड़े प्रवाहों का पता लगाएं। एक प्रक्रिया में बदलाव करने से नीचे के उपयोगकर्ता को नुकसान हो सकता है। चित्र इन निर्भरताओं को दृश्य रूप से दिखाने में मदद करता है। यदि किसी स्टोर में डेटा प्रारूप बदलता है, तो उससे पढ़ने वाली सभी प्रक्रियाओं को अपडेट करना होगा।
दस्तावेजीकरण मानक
नामकरण और लेबलिंग के लिए नियम स्थापित करें। स्थिर नामकरण पद्धति नए टीम सदस्यों के लिए चित्र को पढ़ने योग्य बनाती है। एक स्पष्ट प्रतीकात्मक व्याख्या को किसी विशेष प्रतीक या रेखा प्रकार की व्याख्या करनी चाहिए जो सुरक्षा या प्रदर्शन चिह्नों के लिए उपयोग किया जाता है।
अन्य मॉडल्स के साथ एकीकरण 🤝
डेटा प्रवाह आरेख अकेले नहीं मौजूद होते हैं। वे अन्य मॉडलिंग तकनीकों के पूरक होते हैं।
एंटिटी संबंध आरेख (ERD)
जबकि DFDs गति पर ध्यान केंद्रित करते हैं, ERDs संरचना पर ध्यान केंद्रित करते हैं। उनके आपस में संदर्भ लेने से यह सुनिश्चित होता है कि प्रक्रियाओं के माध्यम से बहने वाले डेटा का डेटाबेस में परिभाषित स्कीमा से मेल खाता है। यदि कोई प्रक्रिया “CustomerID” की अपेक्षा करती है लेकिन ERD में “ClientNum” परिभाषित है, तो असंगतता होती है।
राज्य संक्रमण आरेख
DFDs यह दिखाते हैं कि क्या गतिशील है, लेकिन राज्य आरेख यह दिखाते हैं कि कब। इन दोनों को मिलाकर यह समझने में मदद मिलती है कि डेटा की गति राज्य परिवर्तन को कैसे ट्रिगर करती है। उदाहरण के लिए, “PaymentReceived” प्रवाह “Pending” से “Shipped” तक राज्य परिवर्तन को ट्रिगर कर सकता है।
विश्लेषण विधियों पर निष्कर्ष ✅
डेटा गति मार्गों के विश्लेषण की अनुशासित विधि स्पष्टता और नियंत्रण के बारे में है। यह अमूर्त आवश्यकताओं को वास्तविक आर्किटेक्चरल निर्णयों में बदल देती है। हर तीर का ध्यान से अनुसरण करने और हर परिवर्तन की पुष्टि करने से, आर्किटेक्ट ऐसी प्रणालियां बनाते हैं जो लचीली और समझने योग्य होती हैं।
इस व्यावहार के लिए विस्तार से ध्यान देने की आवश्यकता होती है। यह हर मान्यता को प्रश्न चिन्हित करने की आवश्यकता होती है कि डेटा कहां से आता है और कहां जाता है। सही तरीके से किए जाने पर, परिणामस्वरूप चित्र विकास, परीक्षण और रखरखाव के लिए एक नक्शा बन जाता है। यह व्यवसाय स्टेकहोल्डर्स और तकनीकी टीमों के बीच एक साझा भाषा बन जाता है, जिससे सुनिश्चित होता है कि सभी डेटा के यात्रा को समझते हैं।
जैसे-जैसे प्रणालियां जटिलता में बढ़ती हैं, स्पष्ट मानचित्र की आवश्यकता बढ़ती है। एक अच्छी तरह से विश्लेषित डेटा प्रवाह आरेख सॉफ्टवेयर की लंबी अवधि की स्थिरता में निवेश है। यह डेटा हानि, सुरक्षा उल्लंघन और प्रदर्शन में गिरावट के जोखिम को कम करता है। इन विश्लेषणात्मक मानकों का पालन करके टीमें सुनिश्चित करती हैं कि उनकी प्रणालियां विस्तार के साथ भी मजबूत बनी रहें।