








Los diagramas de flujo de datos (DFD) sirven como plano directriz para los sistemas de información. Representan el movimiento de datos entre procesos, almacenes de datos, entidades externas y los propios datos. Un diagrama bien construido hace más que mostrar hacia dónde van los datos; revela la lógica, la integridad y la seguridad de la arquitectura del sistema. Este artículo examina tres escenarios distintos para ilustrar cómo un modelado riguroso conduce a sistemas estables y mantenibles.
🗺️ Comprendiendo los componentes principales
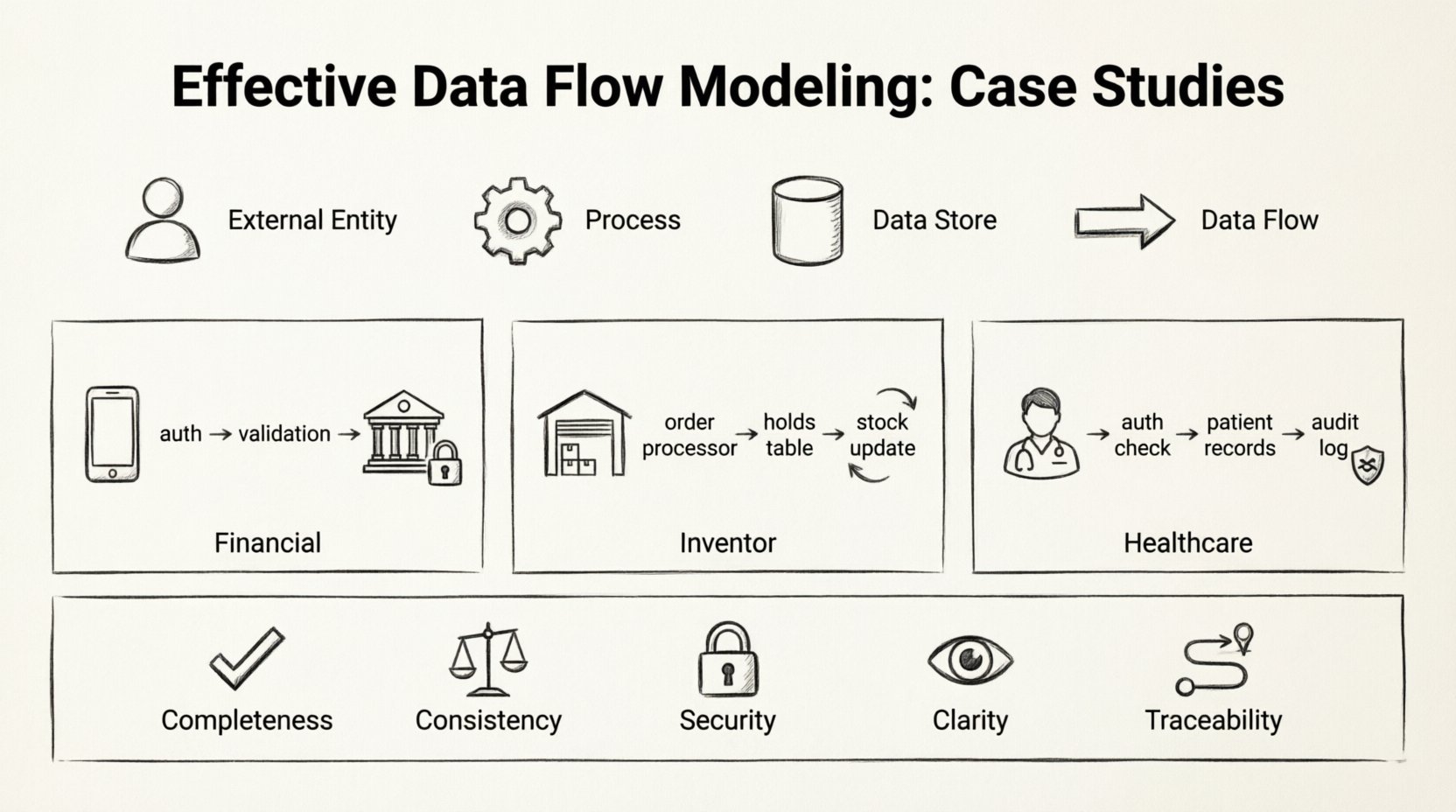
Antes de adentrarnos en implementaciones específicas, es esencial definir los elementos estándar involucrados en cualquier modelo de flujo de datos. Estos componentes permanecen constantes independientemente de la industria o la complejidad del sistema.
- Entidades externas:Fuentes o destinos de datos fuera de los límites del sistema. Podrían ser usuarios, otros sistemas o entidades reguladoras.
- Procesos:Transformaciones que convierten datos de entrada en datos de salida. Cada proceso debe tener al menos una entrada y una salida.
- Almacenes de datos:Ubicaciones donde se almacena la data para su uso posterior. Esto incluye bases de datos, sistemas de archivos o archivos físicos.
- Flujos de datos:Las flechas que conectan los componentes, indicando la dirección y el contenido del movimiento de datos.
La precisión al representar estos elementos es crítica. Etiquetar erróneamente un almacén de datos como un proceso, por ejemplo, puede generar confusión sobre dónde se persiste la data frente a dónde se transforma.
🏦 Estudio de caso 1: Procesamiento de transacciones financieras
El sector financiero exige una alta precisión en cuanto a la integridad y seguridad de los datos. En este escenario, examinamos un sistema diseñado para procesar solicitudes de pago desde una aplicación móvil hasta el núcleo bancario.
🔍 Contexto del sistema
El objetivo principal es garantizar que el dinero solo se mueva cuando se cumplan condiciones específicas. El sistema debe validar los fondos, verificar la identidad del usuario y registrar la transacción con fines de auditoría.
🔄 Desglose del flujo de datos
El proceso de modelado comenzó con un diagrama de Nivel 0, que proporciona una vista de alto nivel del sistema. Esto reveló tres procesos principales:Autenticación, Validación:, y Registro.
- Autenticación:Cuando un usuario inicia una transferencia, sus credenciales se envían al servicio de seguridad. El sistema verifica el estado del usuario frente al almacén de datos Usuarios activosalmacén de datos.
- Validación: Una vez autenticado, la solicitud pasa al proceso de validación. Aquí, el sistema verifica el Saldo de Cuentas almacén para asegurar fondos suficientes. También verifica la Límites de Transacción tabla.
- Registro: Si la validación tiene éxito, la transacción se registra en el Registro de Transacciones almacén de datos. Los Saldo de Cuentas se actualizan, y se envía una señal de confirmación de vuelta al usuario.
Una decisión crítica en este modelo fue la separación de los procesos de Validación y Registro procesos. Fusionarlos crearía un único punto de fallo. Al mantenerlos separados, el sistema puede revertir el estado de validación sin corromper el registro permanente si ocurre una interrupción de red.
📊 Mapeo de Componentes
| Componente | Tipo | Rol en el Sistema |
|---|---|---|
| Aplicación Móvil | Entidad Externa | Inicia la solicitud y recibe la confirmación. |
| Servicio de Seguridad | Proceso | Verifica las credenciales contra el hash almacenado. |
| Saldo de Cuentas | Almacén de Datos | Lee los fondos actuales y escribe los nuevos totales. |
| Registro de Transacciones | Almacén de datos | Registro inmutable de todos los movimientos. |
📦 Estudio de caso 2: Sistema de gestión de inventario
Los sistemas de inventario requieren sincronización entre múltiples ubicaciones. El desafío aquí no consiste únicamente en mover datos, sino en garantizar que la representación del stock físico coincida con el registro digital en tiempo real.
🔍 Contexto del sistema
Este sistema conecta un terminal de gestión de almacén con un portal de ventas en línea. Los datos fluyen en ambas direcciones: las ventas reducen el stock y los envíos entrantes lo aumentan. El modelo debe manejar la concurrencia para evitar ventas excesivas.
🔄 Desglose del flujo de datos
El diagrama de nivel 1 reveló una red compleja de interacciones que involucran alProcesador de pedidos y alControlador de stock.
Cuando se realiza un pedido:
- ElProcesador de pedidos verifica elBase de datos de inventario.
- Si hay stock disponible, se crea unToken de reserva se crea y se almacena en una tabla temporal deTablas de reservas.
- El pedido se confirma al cliente.
- Un proceso independiente,Reconciliación de stock, se ejecuta periódicamente para eliminar las reservas caducadas y actualizar laBase de datos de inventario.
Este enfoque evita que el sistema bloquee toda la base de datos por cada clic. El uso de una tabla temporalTabla de Reservas permite al sistema gestionar la contención sin bloquear a otros usuarios para ver los niveles de inventario.
📊 Manejo de Concurrencia
| Escenario | Acción de Flujo de Datos | Resultado |
|---|---|---|
| Usuario Único | Verificar Stock → Reservar → Confirmar | Éxito |
| Dos Usuarios (Mismo Artículo) | El Usuario A reserva → El Usuario B verifica (Stock Bajo) | El Usuario B ve el recuento actualizado |
| Tiempo de Espera de Reserva | Tabla de Reservas → Proceso de Limpieza | El stock se devuelve al grupo |
El modelo destaca la importancia de la Proceso de Limpieza. Sin esto, la Tabla de Reservas crecería indefinidamente, consumiendo memoria y ralentizando las consultas.
🏥 Estudio de Caso 3: Registros de Pacientes en Salud
La modelización de datos en salud prioriza la privacidad y el control de acceso. El flujo de información debe estar estrictamente regulado según el rol del usuario y la sensibilidad de los datos.
🔍 Contexto del Sistema
Este sistema gestiona el historial de pacientes para una red de clínicas. Los datos incluyen identificación personal, historial médico y resultados de laboratorio. El modelo debe garantizar que solo el personal autorizado pueda ver registros específicos.
🔄 Desglose del Flujo de Datos
El DFD para este sistema introduce el concepto de Control de Acceso como una capa de proceso distinta. Los datos no fluyen directamente desde el registro del paciente hasta la pantalla del médico.
- Solicitud: El médico selecciona un ID de paciente.
- Autorización: El sistema verifica el Permisos del usuario almacén para ver si el médico tiene acceso a los datos de esa clínica específica.
- Recuperación: Si está autorizado, el Motor de consultas recupera datos del Almacén de registros de pacientes almacén.
- Registro: Un registro del evento de acceso se escribe en el Registro de auditoría antes de que se muestren los datos.
Esta separación garantiza que incluso si el almacén de datos se ve comprometido, los registros de acceso proporcionan una huella de quién solicitó qué datos. El Registro de auditoría es un almacén de datos crítico en este modelo, a menudo tratado con un nivel de seguridad más alto que los propios registros médicos.
📊 Niveles de privacidad
| Rol | Acceso a datos | Ruta de flujo de datos |
|---|---|---|
| Recepcionista | Solo horarios | Almacén de horarios → Visualización |
| Enfermera | Vitalicios y medicamentos | Almacén médico → Verificación de autorización → Visualización |
| Especialista | Historia completa | Almacén médico → Verificación de autorización → Visualización |
El diagrama distingue claramente entre el Recepcionista y el Especialistacaminos. Aunque ambos acceden a un paciente, los flujos de datos se filtran de manera diferente. Esta granularidad es esencial para cumplir con las regulaciones de protección de datos.
🛠️ Metodología para una modelización efectiva
Una modelización exitosa requiere un enfoque disciplinado. No se trata únicamente de dibujar cajas y flechas; se trata de comprender la lógica del negocio y traducirla en una representación técnica.
1. Define claramente el alcance
Comience determinando el límite del sistema. ¿Qué es interno y qué es externo? En el estudio de caso financiero, el núcleo bancario era una entidad externa para la capa de la aplicación móvil. Aclarar esto evita el crecimiento del alcance durante el desarrollo.
2. Descomponer gradualmente
Comience con un diagrama de contexto de alto nivel. Luego, expanda cada proceso en un diagrama de nivel 1. Continúe descomponiendo hasta que los procesos sean lo suficientemente simples como para codificarse directamente. Este enfoque jerárquico mantiene el modelo legible.
3. Validar los almacenes de datos
Cada almacén de datos debe tener un propósito claro. Pregunte: ¿Por qué se guarda esta información? ¿Es necesaria para un proceso futuro? Si un almacén de datos no tiene flujos entrantes ni salientes, es un peso muerto. En el caso de inventario, el Tabla de Contenciónestaba justificado por la necesidad de control de concurrencia.
4. Revisar la consistencia
Asegúrese de que los datos que entran en un proceso coincidan con los datos esperados por el siguiente proceso. Los formatos incompatibles o los campos faltantes son fuentes comunes de errores del sistema. Las verificaciones de consistencia deben documentarse dentro de las etiquetas de flujo de datos.
🔄 Mantenimiento y evolución
Los sistemas evolucionan, y los modelos de flujo de datos deben evolucionar con ellos. Un diagrama estático se vuelve obsoleto tan pronto como cambian los requisitos del negocio.
Cuando se introduce una nueva característica, mapee los nuevos flujos de datos contra el diagrama existente. Busque conflictos. Por ejemplo, agregar una característica de notificaciones al sistema financiero podría requerir un nuevo proceso para manejar el envío de correos electrónicos y un nuevo almacén de datos para las plantillas de mensajes.
Se recomienda realizar auditorías regulares del DFD. Compare los registros del sistema real con los flujos de datos planeados. Las discrepancias indican una desviación en la implementación o un modelo desactualizado. Actualizar el modelo asegura que los nuevos desarrolladores puedan entender la arquitectura sin tener que realizar una ingeniería inversa del código.
📋 Resumen de consideraciones clave
La siguiente lista de verificación asegura que los modelos de flujo de datos permanezcan efectivos y precisos durante todo el ciclo de vida del proyecto.
- Compleción:¿Tiene cada proceso entradas y salidas?
- Consistencia:¿Los flujos de datos coinciden en formato y tipo entre los procesos?
- Seguridad:¿Los flujos de datos sensibles están protegidos por procesos de autorización?
- Claridad:¿Son las etiquetas descriptivas y sin ambigüedades?
- Rastreabilidad:¿Puede rastrearse cada pieza de datos hasta su origen y destino?
Al adherirse a estos principios, las organizaciones pueden construir sistemas que sean robustos, seguros y fáciles de mantener. La inversión realizada en un modelado detallado rinde beneficios durante las fases de prueba y despliegue, reduciendo la probabilidad de fallas críticas.
El modelado de flujo de datos es una habilidad fundamental para los arquitectos de sistemas. Cierra la brecha entre los requisitos abstractos y la implementación concreta. Ya sea gestionar transacciones financieras, niveles de inventario o registros de pacientes, la lógica permanece la misma: los datos deben capturarse, transformarse, almacenarse y recuperarse con precisión. Seguir los patrones establecidos en estos estudios de caso proporciona un marco confiable para diseñar sistemas de información complejos.
🚀 Reflexiones finales sobre la arquitectura
La calidad de un sistema a menudo se determina antes de escribir una sola línea de código. Los diagramas creados durante la fase de planificación determinan el rendimiento y la fiabilidad del producto final. Al centrarse en el movimiento de datos, y no solo en el almacenamiento, los arquitectos pueden identificar cuellos de botella y brechas de seguridad desde un principio.
Recuerda que un modelo es una herramienta de comunicación tanto como una especificación técnica. Permite a los interesados visualizar el comportamiento del sistema. Cuando el diagrama es claro, el código sigue de forma natural. Cuando el diagrama es vago, el código se convierte en una pesadilla de mantenimiento.
Aplica estos principios a tu próximo proyecto. Comienza con el contexto, descompone los procesos y verifica los almacenes de datos. Un enfoque disciplinado en el modelado de flujo de datos es la característica distintiva de una práctica de ingeniería madura.