











Создание надежной системы требует не просто визуального соединения компонентов; необходимо строгое логическое подтверждение. При построении диаграммы потоков данных визуальное представление движения информации имеет значение только в той мере, в какой оно опирается на правильную логику. Ошибки на этом этапе проектирования могут привести к серьезным сбоям в работе системы в будущем. Это руководство подробно рассматривает выявление и устранение логических ошибок в проектировании потоков, чтобы обеспечить целостность данных и надежность процессов. 🧠
Понимание основ проектирования потоков 🏗️
Прежде чем выявлять ошибки, необходимо понимать архитектуру стандартной диаграммы потоков данных. Эти диаграммы отображают движение данных через систему, выделяя внешние сущности, процессы, хранилища данных и потоки, их соединяющие. Основная цель — визуализировать, как информация поступает в систему, преобразуется и покидает её. Когда логика, управляющая этими движениями, нарушена, архитектура системы становится нестабильной.
Логические ошибки отличаются от синтаксических ошибок. Синтаксическая ошибка мешает нарисовать диаграмму или проверить её технически. Логическая ошибка означает, что диаграмма нарисована правильно, но отражает невозможную или неэффективную реальность. Например, процесс может быть изображён как получающий входные данные без определённого выхода, или данные могут появляться из ниоткуда. Такие аномалии нарушают логический поток информации. ⚙️
Крайне важно, чтобы диаграмма точно отражала бизнес-правила и законы сохранения данных. Каждый элемент данных, поступающий в процесс, должен быть либо преобразован, либо сохранён, либо передан дальше. Ничто не должно создаваться или уничтожаться без определённого механизма. Этот принцип является основой логической согласованности при проектировании потоков.
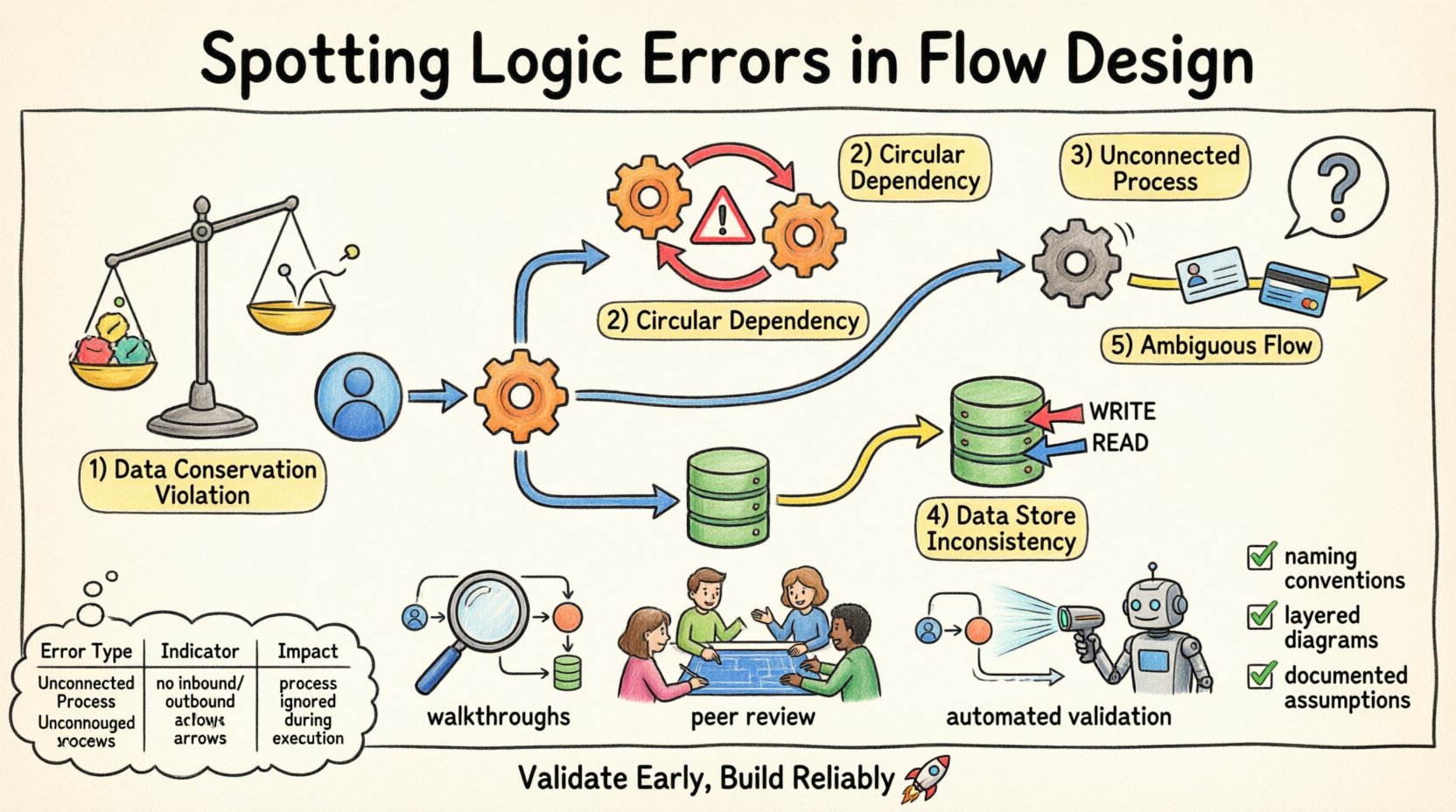
Категории логических ошибок, которые необходимо выявить 🔍
Логические ошибки проявляются в различных формах в проектировании потоков. Распознавание этих категорий помогает систематически проводить проверку. Ниже перечислены основные типы логических несоответствий, которые часто возникают на этапе проектирования.
1. Нарушения закона сохранения данных 📉
Закон сохранения данных гласит, что данные не могут быть созданы или уничтожены внутри процесса. Если диаграмма потоков показывает, что данные появляются из процесса без явного источника, это нарушает этот закон. Напротив, если данные поступают в процесс и исчезают, не будучи сохранёнными или выведены, они теряются. Это часто происходит, когда дизайнер забывает нарисовать стрелку выхода.
Например, если процесс обработки заказов получает данные о заказе, но выводит только подтверждение, то информация о платеже отсутствует. Это указывает на пробел в логике. Система не может функционировать без учёта всех входов и выходов.
2. Циклические зависимости 🔄
Циклические зависимости возникают, когда процесс А поставляет данные процессу Б, который затем возвращает данные обратно процессу А без промежуточного шага. На статической диаграмме это выглядит как петля. Хотя петли существуют в системах, основанных на времени, в логическом проектировании потоков они часто указывают на взаимоблокировку или бесконечную рекурсию, которые система не может разрешить.
Обнаружение таких зависимостей требует отслеживания пути данных. Если процесс зависит от выхода другого процесса, который сам ожидает первый процесс, поток останавливается. Это критическая логическая ошибка, которая останавливает выполнение системы.
3. Не подключённые процессы 🚫
Не подключённый процесс — это процесс, не имеющий входящих потоков данных. Без входа процесс не может выполняться. Это логический остров. Аналогично, процесс без исходящих потоков не вносит вклад в общую выходную информацию системы. Хотя внутренние процессы могут существовать без прямого внешнего выхода, они должны в конечном итоге быть частью цепочки, ведущей к хранилищу данных или внешней сущности.
Изолированные процессы указывают на незавершённое проектирование. Они потребляют ресурсы, но не приносят пользы. Обнаружение таких процессов требует анализа связности каждого узла на диаграмме.
4. Несоответствия в хранилищах данных 🗄️
Хранилища данных представляют постоянную информацию. Логические ошибки возникают, когда процессы читают или записывают в хранилище данных без соответствующего разрешения или контекста. Например, процесс может обновлять запись, не проверив, есть ли у пользователя разрешение, или процесс может читать данные, которые могут быть записаны только другим процессом, который ещё не запущен.
Ещё одна распространённая проблема — одновременное чтение и запись в хранилище данных разными процессами без синхронизации. Это создаёт условия гонки в логической модели. Диаграмма должна чётко показывать пути записи и чтения, чтобы избежать неоднозначности.
5. Неоднозначные потоки данных 🌫️
Потоки данных должны быть чётко названы и описаны. Неоднозначный поток — это поток, несущий несколько типов данных без различия. Если одна стрелка представляет как «ID пользователя», так и «номер кредитной карты», логика нарушена, потому что эти элементы данных имеют разные требования к безопасности и обработке.
Разделение этих потоков гарантирует, что каждый элемент информации обрабатывается в соответствии с его специфическими правилами. Неоднозначность приводит к уязвимостям безопасности и ошибкам обработки в последующих этапах.
| Тип ошибки | Признак | Влияние |
|---|---|---|
| Сохранение данных | Данные появляются/исчезают | Потеря или повреждение данных |
| Циклическая зависимость | Процесс А → Процесс Б → Процесс А | Взаимоблокировка системы |
| Не подключённый процесс | Нет стрелок входа или выхода | Расход ресурсов |
| Несоответствие в хранилище данных | Неуправляемое чтение/запись | Проблемы целостности данных |
| Неоднозначные потоки | Смешанные типы данных в одном потоке | Риски безопасности |
Методологии обнаружения 🛡️
После того как типы ошибок известны, следующий шаг — разработка методологии их обнаружения. Пассивный обзор часто недостаточен. Требуется активное исследование диаграммы.
Пошаговые обходы 🚶
Проведите мысленный обход диаграммы. Начните с внешнего элемента и проследите данные через каждый процесс до хранилища данных или другого элемента. Задавайте вопросы на каждом узле. Достаточно ли входных данных для выполнения этого процесса? Производит ли он ожидаемый выход? Если бы я выполнял эту логику, куда бы направились данные?
Такое ручное прослеживание заставляет проектировщика динамически визуализировать перемещение данных. Оно выявляет пробелы, которые не видны при статическом просмотре. Если обход застревает на каком-либо узле, скорее всего, именно там скрыта логическая ошибка.
Сессии peer-ревью 👥
Другой человек, рассматривающий диаграмму, приносит свежий взгляд. Ревьюер может заметить ошибки, которые проектировщик из-за привычки перестал замечать. Поощряйте ревьюеров ставить под сомнение предпосылки. Попросите их найти поток данных, который кажется избыточным или отсутствующим.
Структурированные сессии ревью снижают вероятность упущений. Во время таких ревью следует использовать чек-лист, чтобы убедиться, что охвачены все категории ошибок.
Автоматические правила валидации 🤖
Хотя здесь не упоминается конкретное программное обеспечение, инструменты проверки логики могут сканировать диаграммы на наличие структурных ошибок. Эти инструменты могут выявлять несвязанные узлы, отсутствующие хранилища данных или циклические ссылки. Они выступают первой линией обороны против базовых логических несогласованностей.
Использование автоматических проверок позволяет команде сосредоточиться на высоком уровне логики, а не на структурной синтаксисе. Это гарантирует прочность основы до добавления сложности.
Стоимость пренебрежения логикой 💸
Почему это важно? Логические ошибки на этапе проектирования самые дорогие в исправлении. Если логическая ошибка обнаруживается во время кодирования, требуется переписывать модули. Если она выявлена после развертывания, требуется накладывать патчи и, возможно, миграция данных.
Рассмотрим ситуацию, когда поток данных не содержит шага проверки. Это позволяет некорректным данным попасть в систему. Позже отчеты, сгенерированные на основе этих данных, оказываются неточными. Бизнес принимает решения на основе неверной информации. Стоимость очистки этих данных и восстановления доверия намного выше, чем стоимость исправления диаграммы на начальном этапе.
Более того, логические ошибки могут привести к нарушениям безопасности. Если поток позволяет данным обойти проверку безопасности, чувствительная информация становится доступной. Это может привести к нарушениям соответствия и юридическим последствиям. Предотвращение таких ошибок — это не только вопрос эффективности, но и управление рисками.
Стратегии профилактики 🛡️
Профилактика лучше, чем обнаружение. Внедрение стандартов и практик на этапе создания диаграммы потоков снижает вероятность возникновения ошибок с самого начала.
Стандартизированные соглашения об именовании 🏷️
Установите строгие правила именования для процессов, хранилищ данных и потоков. Имя процесса должно быть парой глагол-существительное, например, «Проверить заказ». Имя потока должно описывать данные, например, «Сведения о заказе». Такая согласованность облегчает выявление аномалий. Если поток назван «Данные», это, скорее всего, слишком неопределенно и требует тщательного анализа.
Согласованное именование также способствует автоматической валидации. Скрипты могут анализировать имена для проверки соответствия логическим структурам.
Многоуровневое моделирование 📑
Разбейте сложные системы на несколько уровней. Уровень 0 показывает высокий уровень процессов. Уровень 1 раскладывает эти процессы на подпроцессы. Такой иерархический подход предотвращает перегруженность диаграммы. Перегруженность скрывает логические ошибки.
При увеличении определенных участков проектировщик может сосредоточиться на логике конкретной подсистемы, не теряя при этом общей картины. Ошибки легче обнаружить в фокусированных визуализациях.
Документирование предпосылок 📝
Каждая диаграмма сопровождается предпосылками. Документируйте их явно. Если процесс предполагает, что данные всегда присутствуют, укажите это. Если поток подразумевает задержку во времени, зафиксируйте это. Такая документация предоставляет контекст для ревьюеров. Она объясняет, почему были сделаны те или иные логические выборы.
Когда предпосылки документированы, их можно оспорить и проверить на соответствие бизнес-требованиям. Это снижает вероятность того, что скрытые логические ошибки останутся в окончательном проекте.
Чек-лист валидации ✅
Перед окончательным утверждением диаграммы потоков пройдитесь по этому чек-листу. Он охватывает ключевые области, где обычно скрываются логические ошибки.
- Полнота входных данных: Имеет ли каждый процесс хотя бы один входящий поток?
- Полнота выходных данных: Имеет ли каждый процесс хотя бы один исходящий поток?
- Сбалансированность данных: Сохраняется ли объем данных между процессами?
- Нет тупиковых путей: Есть ли какие-либо процессы, которые не ведут к хранилищу данных или внешнему сущности?
- Четкое наименование: Все потоки и процессы названы описательно?
- Безопасность: Чувствительные потоки данных четко обозначены и логически защищены?
- Чувствительность к времени: Явно определены ли какие-либо зависимости по времени?
- Согласованность: Соответствуют ли хранилища данных данным, используемым в процессах?
Уточнение дизайна 🎯
Как только ошибки найдены, начинается процесс уточнения. Он включает в себя изменение диаграммы для исправления логики. Речь не всегда идет об удалении элементов; иногда необходимо добавить недостающие соединения.
Например, если процесс не имеет выхода, определите, куда должны направляться данные. Добавьте недостающую стрелку к соответствующему хранилищу данных или сущности. Если существует циклическая зависимость, введите буфер или очередь для разрыва цикла. Это может означать добавление промежуточного шага в дизайн.
Уточнение является итеративным. После внесения изменений повторно пройдитесь по диаграмме и проверьте список контроля. Убедитесь, что новая логика выдерживает проверку. Не предполагайте, что исправление завершено, пока диаграмма не пройдет все этапы проверки.
Заключительные мысли о логической целостности 💡
Целостность дизайна потока определяет успех системы. Логические ошибки тонкие, но разрушительные. Они подрывают надежность всей архитектуры. Применяя строгие методы обнаружения и стратегии предотвращения, дизайнеры могут создавать системы, функционирующие так, как задумано.
Внимание к деталям на этапе проектирования экономит время, деньги и усилия на последующих этапах. Хорошо проверенная диаграмма — это чертеж стабильной системы. Приоритет логической согласованности обеспечивает правильное, безопасное и эффективное перемещение данных по организации. Такой подход приводит к системам, которые не только функциональны, но и устойчивы к изменениям. 🚀
Сохраняйте фокус на ясности и правильности. Каждая стрелка имеет значение. Каждый узел важен. Следуя этим принципам, дизайн потока становится надежным активом для команды разработчиков.