



हर जटिल प्रणाली विचारों, आवश्यकताओं और सीमाओं के संग्रह के रूप में शुरू होती है। ये आवश्यकताएँ हैं। हालांकि, प्राकृतिक भाषा में लिखी गई आवश्यकताएँ अक्सर अस्पष्ट होती हैं, गलत व्याख्या के लिए झुकी होती हैं और तकनीकी रूप से प्रमाणीकरण करना मुश्किल होता है। जो कुछ स्टेकहोल्डर्स चाहते हैं और जो � ingineers बनाते हैं, उनके बीच के अंतर को पार करने के लिए, हमें एक दृश्य भाषा की आवश्यकता होती है। यहीं डेटा फ्लो डायग्राम (DFD) अनिवार्य हो जाते हैं। 🧭
एक डेटा फ्लो डायग्राम केवल एक ड्राइंग नहीं है; यह एक तार्किक मॉडल है जो जानकारी के प्रणाली के माध्यम से गति को नक्शा बनाता है। यह भौतिक कार्यान्वयन विवरणों को हटाकर डेटा के प्रवाह पर ध्यान केंद्रित करता है। यह लेख कच्ची आवश्यकताओं को एक संरचित, प्रमाणीकृत डेटा फ्लो मॉडल में बदलने की कठोर प्रक्रिया का अध्ययन करता है।
आधार को समझना: आवश्यकता विश्लेषण 📝
एक तीर भी न बनाए जाने से पहले, इनपुट को पूरी तरह समझना आवश्यक है। आवश्यकता विश्लेषण मॉडल के आधार के रूप में खड़ा होता है। एक मजबूत आधार के बिना, ऊपर की संरचना अस्थिर होगी।
कार्यात्मक बनाम गैर-कार्यात्मक आवश्यकताएँ
DFD मुख्य रूप से मॉडल करते हैं कार्यात्मक व्यवहार। वे प्रश्न का उत्तर देते हैं: “प्रणाली डेटा के साथ क्या करती है?” गैर-कार्यात्मक आवश्यकताएँ (जैसे प्रदर्शन, सुरक्षा या लेटेंसी) भौतिक डिज़ाइन को प्रभावित करती हैं लेकिन आमतौर पर DFD में नोड्स के रूप में नहीं दिखाई देती हैं। हालांकि, वे डेटा के प्रवाह के भीतर नियमों को निर्धारित करती हैं।
- कार्यात्मक आवश्यकताएँ:विशिष्ट व्यवहार या कार्य जो प्रणाली को करना है (उदाहरण के लिए, “प्रणाली को क्षेत्र के आधार पर कर गणना करना चाहिए।”)।
- गैर-कार्यात्मक आवश्यकताएँ:गुणवत्ता विशेषताएँ (उदाहरण के लिए, “गणना को 2 सेकंड के भीतर पूरा करना चाहिए।”)।
इनपुट एकत्र करना
मॉडल के लिए जानकारी विभिन्न स्रोतों से आती है। साक्षात्कार, उपयोगकर्ता कहानियाँ और मौजूदा दस्तावेज़ रूपांतरित सामग्री प्रदान करते हैं। लक्ष्य यह निर्धारित करना है कि प्रणाली से बातचीत करने वाले प्रत्येक एकाधिकार और प्रत्येक डेटा के टुकड़े को जो प्रणाली में आता है या बाहर जाता है।
इस जानकारी को एकत्र करते समय, क्रियाओं को देखें। क्रियाएँ अक्सर प्रक्रियाओं को इंगित करती हैं। संज्ञाएँ अक्सर डेटा वस्तुओं या एकाधिकारों को इंगित करती हैं। यह भाषाई संकेत डायग्राम के प्रारंभिक सीमा निर्धारण में मदद करता है।
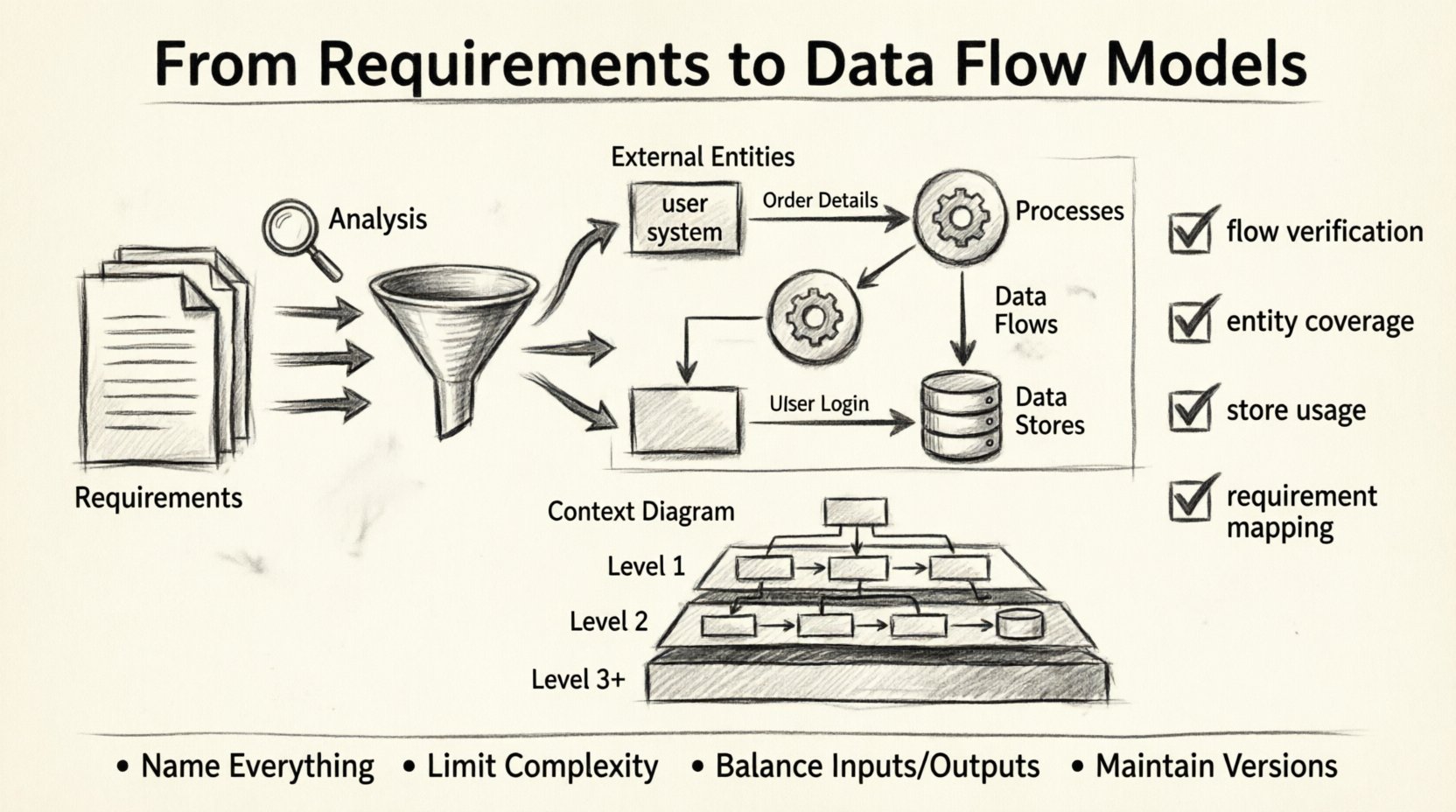
डेटा फ्लो डायग्राम्स की मूल अवधारणाएँ 🗺️
एक वैध मॉडल बनाने के लिए, आपको एक मानक नोटेशन का पालन करना होगा। हालांकि नोटेशन में थोड़ा अंतर हो सकता है, लेकिन मूल अवधारणाएँ स्थिर रहती हैं। डेटा फ्लो डायग्राम के चार प्रमुख घटक हैं।
1. बाहरी एकाधिकार (क्रियाकलाप करने वाले)
ये प्रणाली की सीमा के बाहर डेटा के स्रोत या गंतव्य हैं। वे लोग, अन्य प्रणालियाँ या संगठन हो सकते हैं। DFD में, उन्हें आमतौर पर आयताकार आकृति द्वारा दर्शाया जाता है।
2. प्रक्रियाएँ (रूपांतरण)
प्रक्रियाएँ इनपुट डेटा को आउटपुट डेटा में बदलती हैं। वे प्रणाली के सक्रिय तत्व हैं। DFD में, उन्हें आमतौर पर गोले या गोल आयताकार आकृति द्वारा दर्शाया जाता है। एक प्रक्रिया के कम से कम एक इनपुट और एक आउटपुट होना चाहिए।
3. डेटा प्रवाह (गति)
ये तीर हैं जो डेटा की गति की दिशा दिखाते हैं। वे एकाधिकारों, प्रक्रियाओं और डेटा स्टोर को जोड़ते हैं। प्रत्येक प्रवाह को एक लेबल होना चाहिए जो बताता है कि कौन सी जानकारी गति कर रही है (उदाहरण के लिए, “आदेश विवरण”)।
4. डेटा स्टोर (मेमोरी)
ये वे स्थान हैं जहाँ डेटा बाद में उपयोग के लिए रखा जाता है। वे सक्रिय भंडार हैं। DFD में, उन्हें आमतौर पर खुले छोर वाले आयताकार या समानांतर रेखाओं के रूप में दर्शाया जाता है। डेटा स्टोर कोई क्रिया नहीं शुरू करता है; यह पढ़े जाने या लिखे जाने का इंतजार करता है।
अनुवाद प्रक्रिया: शब्दों से रेखाओं तक 🛠️
पाठ को आरेख में बदलने के लिए एक व्यवस्थित दृष्टिकोण की आवश्यकता होती है। इस प्रक्रिया में विभाजन और सारांश शामिल है। आप पूरी प्रणाली को एक साथ नहीं बनाते हैं। आप ऊपर से शुरू करते हैं और नीचे की ओर जाते हैं।
चरण 1: प्रणाली की सीमा को परिभाषित करें
यह तय करें कि प्रणाली के अंदर क्या है और बाहर क्या है। अंदर की हर चीज एक प्रक्रिया, स्टोर या प्रवाह है। बाहर की हर चीज एक बाहरी एकाधिकार है। यह सीमा संदर्भ को परिभाषित करने के लिए महत्वपूर्ण है।
चरण 2: संदर्भ की पहचान करें
एक “संदर्भ आरेख (जिसे स्तर 0 DFD के रूप में भी जाना जाता है)। यह अधिकतम स्तर के साधारणीकरण को दर्शाता है। यह पूरे प्रणाली को एकल प्रक्रिया के रूप में दिखाता है और इसके बाहरी एजेंसियों के साथ बातचीत को दर्शाता है।
- प्रक्रिया: पूरी प्रणाली का नाम।
- एजेंसियाँ: सभी बाहरी स्रोत और निकास।
- प्रवाह: प्रमुख डेटा इनपुट और आउटपुट।
चरण 3: प्रक्रिया को विभाजित करें
जब संदर्भ स्थापित हो जाता है, तो एकल प्रक्रिया को प्रमुख उप-प्रक्रियाओं में विभाजित करें। यह है स्तर 1 DFD। प्रत्येक उप-प्रक्रिया को आवश्यकताओं से निकली एक विशिष्ट कार्य को संभालना चाहिए। सुनिश्चित करें कि ऊपरी स्तर में प्रवेश करने वाले डेटा को उप-प्रक्रियाओं में से एक में प्रवेश करना चाहिए।
चरण 4: विवरण और भंडार जोड़ें
जैसे आप नीचे की ओर जाते हैं स्तर 2 और उससे आगे, आप डेटा भंडार को शामिल करते हैं। यहीं तर्क विशिष्ट होता है। आप निर्धारित करते हैं कि डेटा चरणों के बीच कहाँ रुकता है। सुनिश्चित करें कि प्रत्येक डेटा भंडार कम से कम एक प्रक्रिया से जुड़ा हो (आप बिना अपडेट या प्राप्त करने के तरीके के भंडार स्थान को बस बना नहीं सकते)।
साधारणीकरण के स्तर समझाए गए 📊
DFD पदानुक्रमिक होते हैं। इससे हितधारकों को अपनी समझ के अनुरूप स्तर पर प्रणाली को देखने की अनुमति मिलती है। निम्नलिखित तालिका मानक स्तरों के बीच अंतरों को स्पष्ट करती है।
| स्तर | परिधि | प्राथमिक ध्यान केंद्र | सामान्य दर्शक |
|---|---|---|---|
| संदर्भ आरेख | पूरी प्रणाली | प्रमुख इनपुट और आउटपुट | हितधारक, प्रबंधन |
| स्तर 1 | प्रमुख कार्य | मुख्य प्रक्रियाएँ और डेटा भंडार | प्रोजेक्ट प्रबंधक, वास्तुकार |
| स्तर 2 | उप-प्रक्रियाएँ | विशिष्ट डेटा रूपांतरण | विकासकर्ता, विश्लेषक |
| स्तर 3+ | परमाणु प्रक्रियाएँ | विस्तृत तर्क प्रवाह | इंजीनियर |
ध्यान दें कि स्तर संख्या बढ़ने के साथ जटिलता बढ़ती है। संदर्भ आरेख एक पक्षी के आंखों के दृष्टिकोण का प्रदर्शन करता है, जबकि गहन स्तर विस्तृत यांत्रिकी प्रदान करते हैं।
संगति और संतुलन सुनिश्चित करना ⚖️
DFD मॉडलिंग में सबसे महत्वपूर्ण नियमों में से एक है संतुलन. जब आप किसी प्रक्रिया को विभाजित करते हैं, तो मूल प्रक्रिया के इनपुट और आउटपुट को बच्चे की प्रक्रियाओं के संयुक्त इनपुट और आउटपुट के साथ मेल बैठाना चाहिए। आप वायु में डेटा का निर्माण या नष्ट करने की अनुमति नहीं दे सकते।
यदि स्तर 1 की प्रक्रिया “उपयोगकर्ता लॉगिन” को इनपुट के रूप में लेती है, तो उसकी एक बच्ची प्रक्रिया को अंततः “उपयोगकर्ता लॉगिन” या उसके व्युत्पन्न संस्करण को स्वीकार करना चाहिए। यदि कोई प्रक्रिया “रिपोर्ट” को आउटपुट करती है, तो उस आउटपुट को मूल आरेख में भी दिखाया जाना चाहिए। इससे पदानुक्रम में तार्किक अखंडता सुनिश्चित होती है।
सत्यापन तकनीकें
आप कैसे जानेंगे कि मॉडल सही है? सत्यापन में कई जांचें शामिल हैं:
- प्रवाह सत्यापन: प्रत्येक तीर का स्रोत से गंतव्य तक अनुसरण करें। क्या यह समझ में आता है? क्या इसके लिए कोई प्रक्रिया है?
- एकाधिकार आवश्यकता: क्या सभी बाहरी एकाधिकार संदर्भ आरेख में दर्शाए गए हैं?
- स्टोर उपयोग: क्या प्रत्येक डेटा स्टोर का उपयोग किया जाता है? अनकड़े स्टोर अक्सर मृत कोड होते हैं।
- आवश्यकता मैपिंग: क्या आप प्रत्येक आवश्यकता को आरेख में किसी प्रक्रिया या प्रवाह तक ट्रेस कर सकते हैं?
डेटा प्रवाह मॉडलिंग में चुनौतियाँ ⚠️
इन मॉडलों को बनाना हमेशा सीधा-सादा नहीं होता है। विश्लेषकों को अक्सर बाधाएँ मिलती हैं जो प्रगति को रोक सकती हैं या असही प्रतिनिधित्व की ओर ले जा सकती हैं।
आवश्यकताओं में अस्पष्टता
यदि प्रारंभिक आवश्यकताएँ धुंधली हैं, तो आरेख भी धुंधला होगा। उदाहरण के लिए, “आदेश प्रक्रिया” बहुत व्यापक है। क्या इसका मतलब “आदेश प्राप्त करना”, “हालत की जांच करना”, या “माल भेजना” है? ये तीन अलग-अलग प्रक्रियाएँ हैं जिनके लिए अलग-अलग नोड्स की आवश्यकता होती है। क्रिया शब्दों की परिभाषा को सुधारना आवश्यक है।
स्कोप क्रीप
मॉडलिंग चरण के दौरान नए आवश्यकताएँ अक्सर उभरती हैं। उन्हें तुरंत जोड़ने की आकर्षण होती है। हालांकि, बहुत सी विस्तार बहुत जल्दी जोड़ने से आरेख भारी हो सकता है। बेहतर है कि नए आवश्यकताओं को बैकलॉग में रिकॉर्ड करें और अगले मॉडल के चरण में उनका समाधान करें।
नियंत्रण प्रवाह के साथ भ्रम
एक सामान्य त्रुटि नियंत्रण तर्क को डेटा प्रवाह के साथ मिलाना है। DFDs दिखाते हैं कि कौन सा डेटा गति करता है, नहीं जब यह गति करता है. नियंत्रण प्रवाह आरेख (जैसे प्रवाहचित्र) तर्क शाखाओं (if/else) को दिखाते हैं। DFDs मानते हैं कि प्रक्रिया होती है; वे सिर्फ डेटा के पार जाने को दिखाते हैं। निर्णय तर्क के बजाय डेटा प्रतिबंध पर ध्यान केंद्रित रखें।
समय के साथ मॉडल का रखरखाव 🔄
आवश्यकताएं बदलती हैं। प्रणालियां विकसित होती हैं। एक DFD एक स्थिर कलाकृति नहीं है जिसे एक बार बनाकर रख दिया जाए। इसे एक जीवंत दस्तावेज के रूप में बनाए रखना होगा।
जब कोई आवश्यकता बदलती है, तो प्रभाव का पता लगाएं। यदि एक नया डेटा क्षेत्र जोड़ा जाता है, तो क्या इससे प्रवाह में परिवर्तन आता है? क्या इसके लिए एक नया स्टोर आवश्यक है? तुरंत आरेख को अपडेट करें। इससे दस्तावेजीकरण वास्तविकता के साथ समान रहता है।
संस्करण नियंत्रण भी आवश्यक है। जैसे-जैसे मॉडल बढ़ता है, पुराने संस्करण लेखापरीक्षा या पुरानी तर्क को समझने के लिए महत्वपूर्ण हो जाते हैं। संस्करणों को लेबल करना (उदाहरण के लिए, DFD_v1.0, DFD_v2.0) सिस्टम डिजाइन के विकास को ट्रैक करने में मदद करता है।
स्पष्टता के लिए सर्वोत्तम प्रथाएं ✨
मॉडल के उद्देश्य को सुनिश्चित करने के लिए, प्रभावी संचार के लिए इन दिशानिर्देशों का पालन करें।
- सब कुछ का नाम रखें:एंटिटीज, प्रक्रियाएं और प्रवाहों के स्पष्ट, वर्णनात्मक नाम होने चाहिए। संक्षिप्त रूपों से बचें, जब तक वे उद्योग मानक न हों।
- जटिलता को सीमित रखें:यदि एक प्रक्रिया में सात से अधिक इनपुट या आउटपुट हैं, तो यह अधिक जटिल होने की संभावना है। इसे और अधिक विभाजित करें।
- प्रतिच्छेदन वाली रेखाओं को कम करें:हमेशा संभव नहीं होता है, लेकिन आरेख को इस तरह व्यवस्थित करने की कोशिश करें कि तीर अत्यधिक प्रतिच्छेदन न करें। इससे पठनीयता में सुधार होता है।
- स्थिर प्रतीकों का उपयोग करें:दस्तावेज के पूरे भाग में एक ही नोटेशन शैली (उदाहरण के लिए, गेन एंड सर्सन या योर्डन एंड डेमार्को) का उपयोग करें।
प्रणाली डिजाइन पर निष्कर्ष 🏁
आवश्यकताओं से डेटा प्रवाह मॉडल तक का सफर स्पष्टता की एक विद्या है। इसमें कार्यान्वयन की आवाज़ को हटाकर सूचना के मूल आंदोलन को देखने की आवश्यकता होती है। विभाजन, संतुलन और प्रमाणीकरण के सिद्धांतों का पालन करके, आप एक नक्शा बनाते हैं जिस पर इंजीनियर भरोसा कर सकते हैं और स्टेकहोल्डर समझ सकते हैं।
यह मॉडल डेटाबेस डिजाइन, API परिभाषाओं और इंटरफेस विवरण के लिए संदर्भ बिंदु बन जाता है। यह परियोजना को वास्तविकता में जमा देता है। जब आवश्यकताएं ठोस होती हैं, तो आरेख टीम को गंतव्य तक ले जाने वाला नक्शा होता है। डेटा पर ध्यान केंद्रित रखें, सीमाओं का सम्मान करें, और सुनिश्चित करें कि प्रत्येक तीर एक कहानी कहता है।