









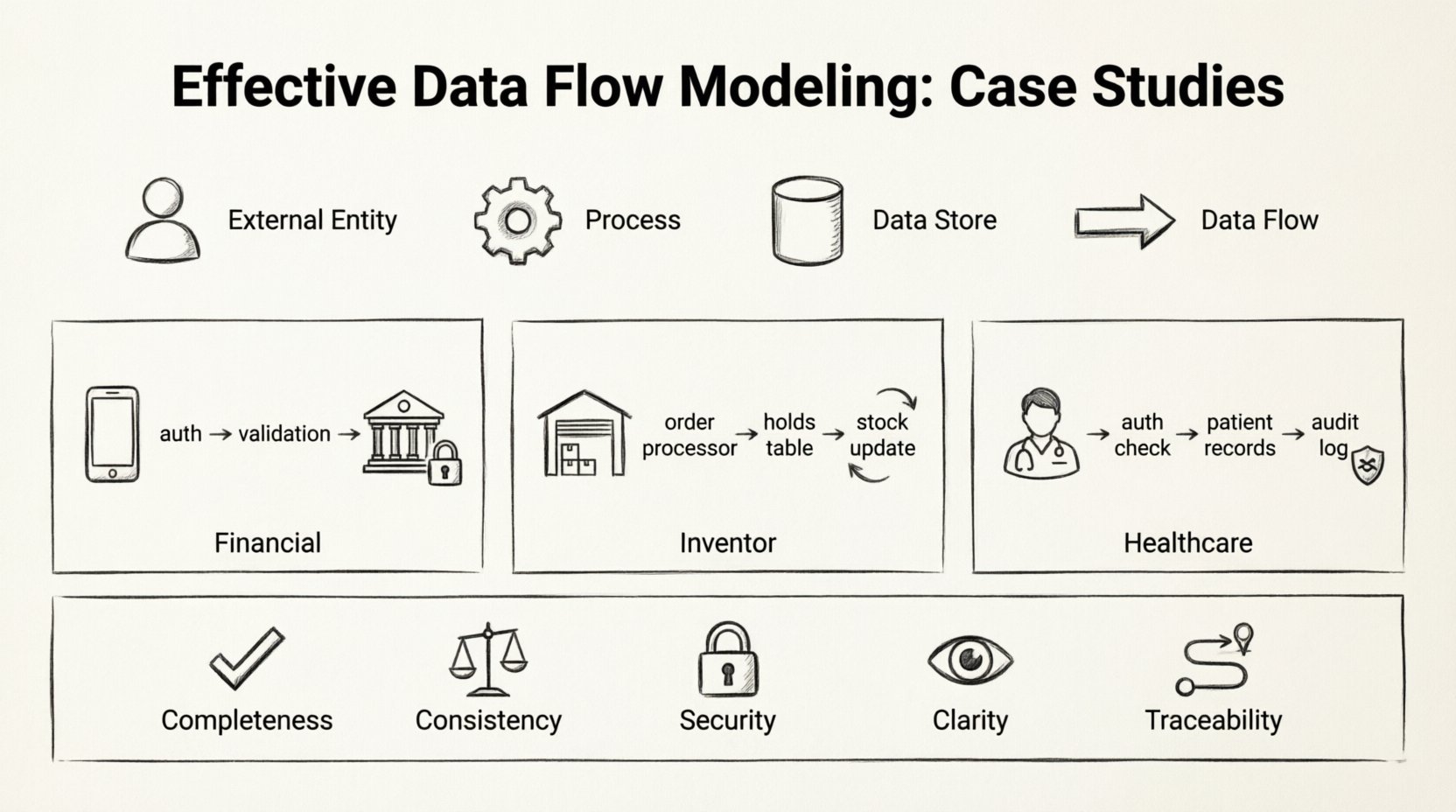
डेटा फ्लो डायग्राम (DFD) सूचना प्रणालियों के लिए ब्लूप्रिंट के रूप में कार्य करते हैं। वे प्रक्रियाओं, डेटा स्टोर, बाहरी एजेंसियों और डेटा के बीच डेटा के आंदोलन को नक्शा बनाते हैं। एक अच्छी तरह से निर्मित आरेख केवल यह दिखाने से अधिक करता है कि डेटा कहाँ जाता है; यह प्रणाली संरचना की तर्क, अखंडता और सुरक्षा को उजागर करता है। इस लेख में तीन अलग-अलग परिदृश्यों का अध्ययन किया गया है ताकि यह स्पष्ट किया जा सके कि कितनी सख्त मॉडलिंग स्थिर, रखरखाव योग्य प्रणालियों को लाने में मदद करती है।
🗺️ मूल घटकों को समझना
विशिष्ट कार्यान्वयन में डुबकी लगाने से पहले, किसी भी डेटा फ्लो मॉडल में शामिल मानक तत्वों को परिभाषित करना आवश्यक है। ये घटक उद्योग या प्रणाली की जटिलता के बावजूद स्थिर रहते हैं।
- बाहरी एजेंसियाँ:प्रणाली सीमा के बाहर डेटा के स्रोत या गंतव्य। इनमें उपयोगकर्ता, अन्य प्रणालियाँ या नियामक निकाय शामिल हो सकते हैं।
- प्रक्रियाएँ:इनपुट डेटा को आउटपुट डेटा में बदलने वाले परिवर्तन। प्रत्येक प्रक्रिया के कम से कम एक इनपुट और एक आउटपुट होना चाहिए।
- डेटा स्टोर:वे स्थान जहाँ डेटा बाद में उपयोग के लिए रखा जाता है। इसमें डेटाबेस, फाइल प्रणाली या भौतिक आर्काइव शामिल हैं।
- डेटा प्रवाह:घटकों को जोड़ने वाली तीर, जो डेटा के आंदोलन की दिशा और सामग्री को इंगित करते हैं।
इन तत्वों के प्रतिनिधित्व में सटीकता आवश्यक है। उदाहरण के लिए, डेटा स्टोर को प्रक्रिया के रूप में गलत नाम देने से यह भ्रम में डाल सकता है कि डेटा कहाँ स्थायी रूप से रखा जाता है और कहाँ बदला जाता है।
🏦 केस स्टडी 1: वित्तीय लेनदेन प्रसंस्करण
वित्तीय क्षेत्र डेटा अखंडता और सुरक्षा के संबंध में उच्च सटीकता की मांग करता है। इस परिदृश्य में, हम एक प्रणाली का अध्ययन करते हैं जिसका उद्देश्य मोबाइल एप्लिकेशन से बैंकिंग कोर को भुगतान अनुरोध प्रसंस्करण करना है।
🔍 प्रणाली संदर्भ
मुख्य लक्ष्य यह सुनिश्चित करना है कि पैसा केवल तभी ही चले जब विशिष्ट शर्तें पूरी हों। प्रणाली को धन की पुष्टि करनी, उपयोगकर्ता पहचान की पुष्टि करनी और लेनदेन को लेनदेन के लिए रिकॉर्ड करना होगा।
🔄 डेटा फ्लो विभाजन
मॉडलिंग प्रक्रिया लेवल 0 डायग्राम के साथ शुरू हुई, जो प्रणाली के एक उच्च स्तरीय दृश्य को प्रदान करता है। इसने तीन मुख्य प्रक्रियाओं को उजागर किया: प्रमाणीकरण, पुष्टि:, और पोस्टिंग.
- प्रमाणीकरण:जब उपयोगकर्ता एक स्थानांतरण शुरू करता है, तो उनके प्रमाण पत्र सुरक्षा सेवा को भेजे जाते हैं। प्रणाली उपयोगकर्ता की स्थिति को सक्रिय उपयोगकर्ता डेटा स्टोर के बारे में जांचती है।
- पुष्टि: एक बार प्रमाणित करने के बाद, अनुरोध मान्यता प्रक्रिया में आगे बढ़ता है। यहाँ, प्रणाली जांच करती है कि खाता शेष भंडार से सुनिश्चित करने के लिए पर्याप्त धन है। इसके अलावा यह जांचती है कि लेनदेन सीमाएँ तालिका।
- प्रकाशन: यदि मान्यता पारित होती है, तो लेनदेन को लेनदेन लॉग डेटा भंडार में दर्ज किया जाता है। खाता शेष को अद्यतन किया जाता है, और उपयोगकर्ता को वापस पुष्टि संकेत भेजा जाता है।
इस मॉडल में एक महत्वपूर्ण निर्णय था मान्यता और प्रकाशन प्रक्रियाओं को अलग करना। उन्हें मिलाने से एकल विफलता का बिंदु बन जाता। उन्हें अलग रखने से प्रणाली नेटवर्क अवरोध के मामले में मान्यता स्थिति को वापस ले सकती है बिना स्थायी लॉग को दूषित किए।
📊 घटक नक्शा
| घटक | प्रकार | प्रणाली में भूमिका |
|---|---|---|
| मोबाइल ऐप | बाहरी एकाधिकार | अनुरोध शुरू करता है और पुष्टि प्राप्त करता है। |
| सुरक्षा सेवा | प्रक्रिया | संग्रहीत हैश के विरुद्ध प्रमाणपत्र की जांच करता है। |
| खाता शेष | डेटा भंडार | वर्तमान धन को पढ़ता है और नए कुल राशि को लिखता है। |
| लेनदेन लॉग | डेटा स्टोर | सभी गतिविधियों का अपरिवर्तनीय रिकॉर्ड। |
📦 केस स्टडी 2: इन्वेंट्री मैनेजमेंट सिस्टम
इन्वेंट्री सिस्टम में कई स्थानों के बीच समन्वय की आवश्यकता होती है। यहाँ चुनौती केवल डेटा को ले जाने के बारे में नहीं है, बल्कि भौतिक स्टॉक के प्रतिनिधित्व को वास्तविक समय में डिजिटल रिकॉर्ड के साथ मेल खाने के बारे में है।
🔍 सिस्टम संदर्भ
यह सिस्टम एक वेयरहाउस मैनेजमेंट टर्मिनल को ऑनलाइन सेल्स पोर्टल से जोड़ता है। डेटा द्विदिशात्मक रूप से प्रवाहित होता है: बिक्री स्टॉक को कम करती है, और आने वाले शिपमेंट इसे बढ़ाते हैं। मॉडल को समानांतरता को संभालना होगा ताकि अतिरिक्त बिक्री से बचा जा सके।
🔄 डेटा प्रवाह विश्लेषण
लेवल 1 आरेख ने एक जटिल बातचीत के जाल का खुलासा किया जिसमें शामिल हैऑर्डर प्रोसेसर औरस्टॉक कंट्रोलर.
जब कोई ऑर्डर दिया जाता है:
- वहऑर्डर प्रोसेसर जांचता हैइन्वेंट्री डेटाबेस.
- यदि स्टॉक उपलब्ध है, तो एकरिजर्वेशन टोकन बनाया जाता है और एक अस्थायीहोल्ड्स टेबल.
- ग्राहक को ऑर्डर की पुष्टि कर दी जाती है।
- एक अलग प्रक्रिया,स्टॉक रिकॉन्सिलिएशन, नियमित रूप से चलती है ताकि एक्सपायर हुए रिजर्वेशन को साफ किया जा सके औरइन्वेंट्री डेटाबेस.
इस दृष्टिकोण से सिस्टम को हर क्लिक के लिए पूरे डेटाबेस को लॉक करने से बचाया जाता है। अस्थायीहोल्ड्स टेबल सिस्टम को संघर्ष को बिना अन्य उपयोगकर्ताओं के इन्वेंटरी स्तर देखने से रोके बिना प्रबंधित करने में सक्षम बनाता है।
📊 समानांतरता प्रबंधन
| परिदृश्य | डेटा प्रवाह क्रिया | परिणाम |
|---|---|---|
| एकल उपयोगकर्ता | स्टॉक जांचें → आरक्षित करें → पुष्टि करें | सफलता |
| दो उपयोगकर्ता (एक ही वस्तु) | उपयोगकर्ता A आरक्षित करता है → उपयोगकर्ता B जांचता है (स्टॉक कम) | उपयोगकर्ता B अपडेटेड गिनती देखता है |
| आरक्षण समय सीमा समाप्त | होल्ड्स टेबल → साफ़ करने की प्रक्रिया | स्टॉक पूल में वापस कर दिया गया |
मॉडल महत्वपूर्ण बात को उजागर करता है साफ़ करने की प्रक्रिया बिना इसके, वह होल्ड्स टेबल अनंत तक बढ़ता रहेगा, मेमोरी का उपयोग करेगा और प्रश्नों को धीमा करेगा।
🏥 केस स्टडी 3: स्वास्थ्य सेवा रोगी रिकॉर्ड
स्वास्थ्य सेवा डेटा मॉडलिंग गोपनीयता और पहुंच नियंत्रण पर बल देती है। सूचना के प्रवाह को उपयोगकर्ता की भूमिका और डेटा की संवेदनशीलता के आधार पर सख्ती से नियंत्रित किया जाना चाहिए।
🔍 सिस्टम संदर्भ
यह सिस्टम क्लिनिक के नेटवर्क के लिए रोगी इतिहास का प्रबंधन करता है। डेटा में व्यक्तिगत पहचान, चिकित्सा इतिहास और प्रयोगशाला परिणाम शामिल हैं। मॉडल को सुनिश्चित करना होगा कि केवल अधिकृत कर्मचारी ही विशिष्ट रिकॉर्ड देख सकते हैं।
🔄 डेटा प्रवाह विश्लेषण
इस सिस्टम के लिए DFD अवधारणा को पेश करता है पहुंच नियंत्रण एक अलग प्रक्रिया परत के रूप में। डेटा सीधे रोगी रिकॉर्ड से डॉक्टर की स्क्रीन पर नहीं बहता है।
- अनुरोध: डॉक्टर एक रोगी आईडी चुनता है।
- प्राधिकरण: प्रणाली जांचती है किउपयोगकर्ता की अनुमतियाँ स्टोर को देखने के लिए कि क्या डॉक्टर को उस विशिष्ट क्लिनिक के डेटा तक पहुंच है।
- प्राप्त करना: यदि अनुमति दी गई है, तोप्रश्न इंजन डेटा को लेता हैरोगी के रिकॉर्ड स्टोर से।
- लॉगिंग: पहुंच घटना का रिकॉर्ड लिखा जाता हैऑडिट लॉग डेटा प्रदर्शित करने से पहले।
इस अलगाव सुनिश्चित करता है कि यद्यपि डेटा स्टोर को नुकसान पहुंचा हो, तो एक्सेस लॉग यह बताते हैं कि किसने किस डेटा का अनुरोध किया।ऑडिट लॉग इस मॉडल में एक महत्वपूर्ण डेटा स्टोर है, जिसे अक्सर चिकित्सा रिकॉर्ड्स की तुलना में अधिक सुरक्षा स्तर प्राप्त होता है।
📊 गोपनीयता स्तर
| भूमिका | डेटा पहुंच | डेटा प्रवाह मार्ग |
|---|---|---|
| रिसेप्शनिस्ट | केवल शेड्यूल | शेड्यूल स्टोर → प्रदर्शन |
| नर्स | जीवन संकेत और दवाएं | चिकित्सा स्टोर → प्राधिकरण जांच → प्रदर्शन |
| विशेषज्ञ | पूर्ण इतिहास | चिकित्सा स्टोर → प्राधिकरण जांच → प्रदर्शन |
आरेख स्पष्ट रूप से बीच के अंतर को दर्शाता हैरिसेप्शनिस्ट और विशेषज्ञ मार्ग। भले ही दोनों एक मरीज तक पहुँचते हैं, लेकिन डेटा स्ट्रीम को अलग-अलग तरीके से फ़िल्टर किया जाता है। डेटा सुरक्षा नियमों के अनुपालन के लिए इस विस्तार की आवश्यकता होती है।
🛠️ प्रभावी मॉडलिंग के लिए विधि
सफल मॉडलिंग के लिए एक अनुशासित दृष्टिकोण की आवश्यकता होती है। यह सिर्फ बॉक्स और तीर बनाने के बारे में नहीं है; यह व्यापार तर्क को समझने और उसे तकनीकी प्रतिनिधित्व में बदलने के बारे में है।
1. सीमा को स्पष्ट रूप से परिभाषित करें
सबसे पहले सिस्टम की सीमा तय करें। क्या आंतरिक है और क्या बाहरी है? वित्तीय अध्ययन में, बैंकिंग कोर मोबाइल ऐप परत के लिए एक बाहरी एकाइट था। इसकी स्पष्टता विकास के दौरान सीमा विस्तार को रोकती है।
2. धीरे-धीरे विभाजित करें
एक उच्च स्तर के संदर्भ आरेख से शुरू करें। फिर प्रत्येक प्रक्रिया को लेवल 1 आरेख में विस्तारित करें। जब तक प्रक्रियाएं इतनी सरल नहीं हो जातीं कि सीधे कोड किया जा सके, विभाजन जारी रखें। इस पदानुक्रमिक दृष्टिकोण से मॉडल पठनीय बना रहता है।
3. डेटा स्टोर की पुष्टि करें
प्रत्येक डेटा स्टोर को स्पष्ट उद्देश्य होना चाहिए। पूछें: इस डेटा को क्यों सहेजा जा रहा है? क्या भविष्य की प्रक्रिया के लिए इसकी आवश्यकता है? यदि किसी डेटा स्टोर में कोई आगमन या निर्गमन प्रवाह नहीं है, तो वह बेकार का भार है। इन्वेंट्री के मामले में, होल्ड्स टेबल समानांतर नियंत्रण की आवश्यकता के कारण वैध था।
4. संगतता के लिए समीक्षा करें
यह सुनिश्चित करें कि प्रक्रिया में प्रवेश करने वाले डेटा का आकार और प्रकार अगली प्रक्रिया द्वारा अपेक्षित डेटा के साथ मेल खाता हो। असंगत प्रारूप या गायब फ़ील्ड तंत्र के त्रुटियों के सामान्य कारण हैं। संगतता जांच को डेटा प्रवाह लेबल के भीतर दर्ज किया जाना चाहिए।
🔄 रखरखाव और विकास
तंत्र विकसित होते हैं, और डेटा प्रवाह मॉडल को उनके साथ विकसित होना चाहिए। जैसे ही व्यापार आवश्यकताएं बदलती हैं, एक स्थिर आरेख अप्रासंगिक हो जाता है।
जब कोई नया फीचर जोड़ा जाता है, तो मौजूदा आरेख के बारे में नए डेटा प्रवाह को नक्शा बनाएं। संघर्षों की तलाश करें। उदाहरण के लिए, वित्तीय प्रणाली में सूचना फीचर जोड़ने के लिए ईमेल डिलीवरी के लिए एक नई प्रक्रिया और संदेश टेम्पलेट के लिए एक नया डेटा स्टोर की आवश्यकता हो सकती है।
DFD के नियमित ऑडिट की सिफारिश की जाती है। वास्तविक सिस्टम लॉग की योजित डेटा प्रवाह के साथ तुलना करें। अंतर या तो कार्यान्वयन में विचलन या पुराने मॉडल को इंगित करते हैं। मॉडल को अपडेट करने से यह सुनिश्चित होता है कि नए विकासकर्ता कोड को उलटे डिजाइन किए बिना आर्किटेक्चर को समझने में सक्षम हों।
📋 मुख्य विचारों का सारांश
निम्नलिखित चेकलिस्ट सुनिश्चित करती है कि डेटा प्रवाह मॉडल प्रोजेक्ट के जीवनचक्र के दौरान प्रभावी और सटीक रहें।
- पूर्णता: क्या प्रत्येक प्रक्रिया के इनपुट और आउटपुट हैं?
- संगतता: क्या प्रक्रियाओं के बीच डेटा प्रवाह का प्रारूप और प्रकार मेल खाता है?
- सुरक्षा: क्या संवेदनशील डेटा प्रवाह प्राधिकरण प्रक्रियाओं द्वारा सुरक्षित हैं?
- स्पष्टता: क्या लेबल वर्णनात्मक और अस्पष्ट नहीं हैं?
- ट्रेसेबिलिटी: क्या प्रत्येक डेटा के स्रोत और गंतव्य तक ट्रेस किया जा सकता है?
इन सिद्धांतों का पालन करके संगठन ऐसे प्रणालियां बना सकते हैं जो बलवान, सुरक्षित और रखरखाव में आसान हों। विस्तृत मॉडलिंग में निवेश की गई मेहनत परीक्षण और डेप्लॉयमेंट चरणों में लाभ देती है, जिससे महत्वपूर्ण विफलताओं की संभावना कम हो जाती है।
डेटा प्रवाह मॉडलिंग सिस्टम वार्डों के लिए एक मूलभूत कौशल है। यह अमूर्त आवश्यकताओं और वास्तविक कार्यान्वयन के बीच के अंतर को पार करती है। चाहे वित्तीय लेनदेन, स्टॉक स्तर या मरीज के रिकॉर्ड का प्रबंधन करना हो, तर्क एक ही रहता है: डेटा को सटीकता के साथ एकत्र किया, परिवर्तित किया, संग्रहीत किया और पुनर्प्राप्त किया जाना चाहिए। इन केस स्टडी में स्थापित पैटर्न का पालन करने से जटिल सूचना प्रणालियों के डिज़ाइन के लिए एक विश्वसनीय ढांचा प्राप्त होता है।
🚀 आर्किटेक्चर पर अंतिम विचार
एक प्रणाली की गुणवत्ता अक्सर एक लाइन कोड लिखे जाने से पहले ही निर्धारित हो जाती है। योजना चरण के दौरान बनाए गए डायग्राम अंतिम उत्पाद के प्रदर्शन और विश्वसनीयता को निर्धारित करते हैं। डेटा के भंडारण के बजाय उसके आंदोलन पर ध्यान केंद्रित करके, वार्ड बाधाओं और सुरक्षा की कमियों को जल्दी से पहचान सकते हैं।
याद रखें कि एक मॉडल तकनीकी विवरण के बराबर एक संचार उपकरण भी है। यह स्टेकहोल्डर्स को प्रणाली के व्यवहार को देखने में सक्षम बनाता है। जब डायग्राम स्पष्ट होता है, तो कोड प्राकृतिक रूप से आता है। जब डायग्राम धुंधला होता है, तो कोड रखरखाव का दुर्भाग्य बन जाता है।
अपने अगले प्रोजेक्ट में इन सिद्धांतों को लागू करें। संदर्भ से शुरू करें, प्रक्रियाओं को तोड़ें, और डेटा स्टोर की पुष्टि करें। डेटा प्रवाह मॉडलिंग के लिए एक अनुशासित दृष्टिकोण परिपक्व � ingineering प्रथा की पहचान है।