











Diseñar un sistema robusto requiere más que simplemente conectar componentes visualmente; exige una verificación lógica rigurosa. Al construir un Diagrama de Flujo de Datos, la representación visual del movimiento de información solo es tan buena como la lógica que la impulsa. Los errores en esta fase de diseño pueden propagarse hasta causar fallas operativas importantes más adelante. Esta guía ofrece una revisión profunda sobre cómo identificar y corregir errores lógicos dentro de los diseños de flujo para garantizar la integridad de los datos y la confiabilidad del proceso. 🧠
Comprendiendo la base del diseño de flujos 🏗️
Antes de identificar errores, uno debe comprender la arquitectura de un Diagrama de Flujo de Datos estándar. Estos diagramas representan el movimiento de datos a través de un sistema, destacando entidades externas, procesos, almacenes de datos y los flujos que los conectan. El propósito principal es visualizar cómo la información entra, se transforma y sale de un sistema. Cuando la lógica que rige estos movimientos está defectuosa, la arquitectura del sistema resultante se vuelve inestable.
Los errores lógicos difieren de los errores de sintaxis. Un error de sintaxis impide que un diagrama se dibuje o se valide técnicamente. Un error lógico implica que el diagrama está dibujado correctamente, pero representa una realidad imposible o ineficiente. Por ejemplo, un proceso podría representarse como que recibe entrada sin una salida definida, o los datos podrían aparecer de la nada. Estas anomalías interrumpen el flujo lógico de la información. ⚙️
Es fundamental asegurarse de que el diagrama refleje con precisión las reglas del negocio y las leyes de conservación de datos. Cada pieza de datos que entra en un proceso debe ser transformada, almacenada o transmitida. Nada debe crearse ni destruirse sin un mecanismo definido. Este principio es la columna vertebral de la consistencia lógica en el diseño de flujos.
Categorías de errores lógicos que detectar 🔍
Los errores lógicos se manifiestan de diversas formas dentro de un diseño de flujo. Reconocer estas categorías ayuda en una revisión sistemática. A continuación se presentan los tipos principales de inconsistencias lógicas que frecuentemente aparecen durante la fase de diseño.
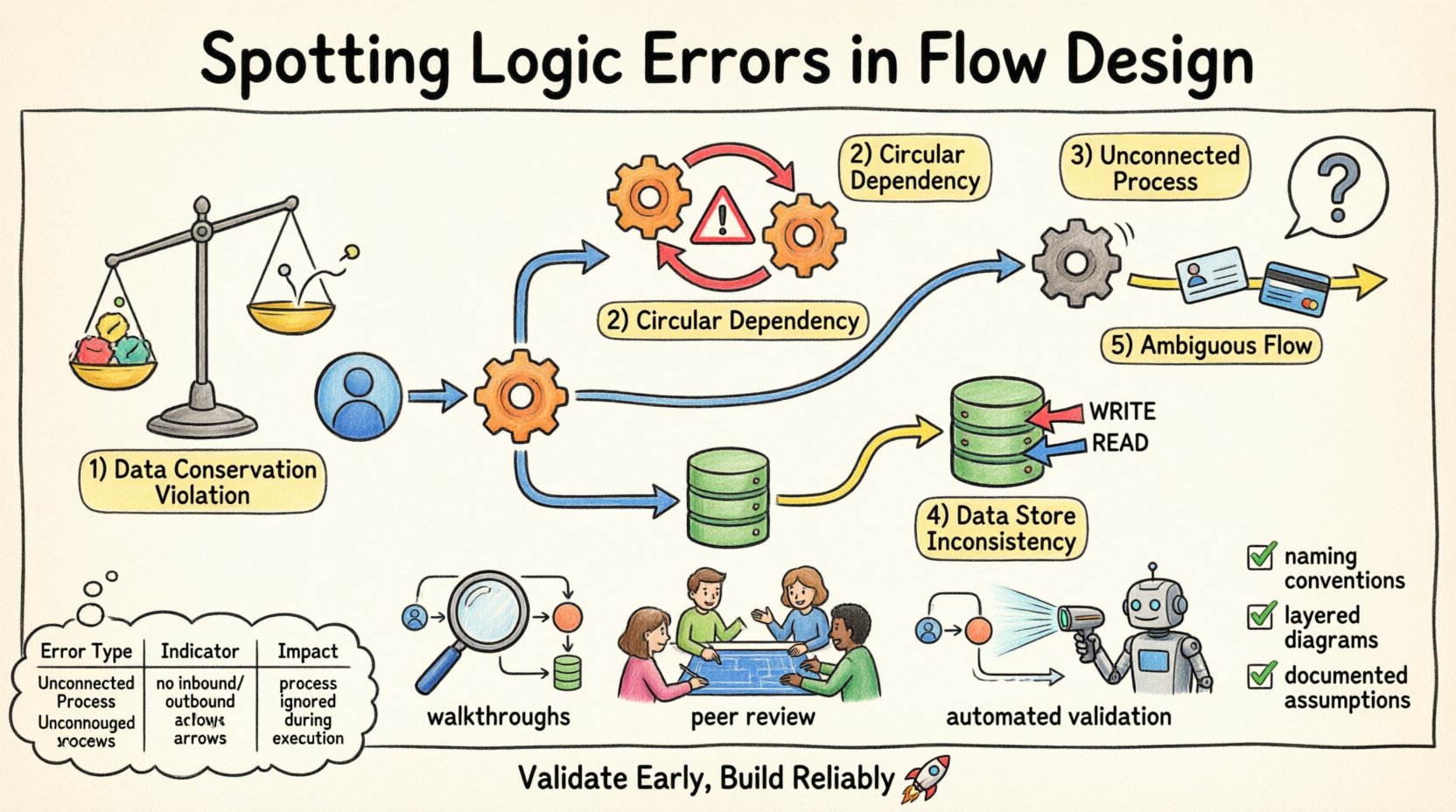
1. Violaciones de la conservación de datos 📉
La ley de conservación de datos establece que los datos no pueden crearse ni destruirse dentro de un proceso. Si un diagrama de flujo muestra datos que emergen de un proceso sin una fuente clara, viola esta ley. Por el contrario, si los datos entran en un proceso y desaparecen sin ser almacenados ni enviados, se pierden. Esto suele ocurrir cuando un diseñador olvida dibujar una flecha de salida.
Por ejemplo, si un proceso de pedido de cliente recibe los detalles del pedido pero solo envía un comprobante de confirmación, la información de pago está ausente. Esto indica una brecha en la lógica. El sistema no puede funcionar sin tener en cuenta todas las entradas y salidas.
2. Dependencias circulares 🔄
Las dependencias circulares ocurren cuando el Proceso A alimenta datos al Proceso B, que luego alimenta datos de vuelta al Proceso A sin una etapa intermedia. En un diagrama estático, esto se ve como un bucle. Aunque los bucles existen en sistemas basados en el tiempo, en un diseño de flujo lógico, a menudo indican un bloqueo (deadlock) o una recursión infinita que el sistema no puede resolver.
Identificar estos casos requiere rastrear la ruta de los datos. Si un proceso depende de la salida de otro proceso que a su vez está esperando al primer proceso, el flujo se detiene. Este es un error lógico crítico que detiene la ejecución del sistema.
3. Procesos no conectados 🚫
Un proceso no conectado es aquel que no tiene flujos de datos entrantes. Sin entrada, un proceso no puede ejecutarse. Es una isla lógica. De manera similar, un proceso sin flujos salientes no contribuye a la salida general del sistema. Aunque pueden existir procesos internos sin salida externa directa, deben alimentar eventualmente una cadena que llegue a un almacén de datos o entidad externa.
Los procesos aislados indican un diseño incompleto. Consumen recursos pero no aportan valor. Encontrarlos requiere un análisis de conectividad de cada nodo en el diagrama.
4. Inconsistencias en el almacén de datos 🗄️
Los almacenes de datos representan información persistente. Los errores lógicos surgen cuando los procesos leen o escriben en un almacén de datos sin autorización o contexto adecuados. Por ejemplo, un proceso podría actualizar un registro sin verificar si el usuario tiene permiso, o un proceso podría leer datos que solo son escritos por otro proceso que aún no se ha ejecutado.
Otro problema común es que un almacén de datos sea leído y escrito simultáneamente por diferentes procesos sin sincronización. Esto genera condiciones de carrera en el modelo lógico. El diagrama debe mostrar rutas claras de escritura y lectura para evitar ambigüedades.
5. Flujos de datos ambiguos 🌫️
Los flujos de datos deben nombrarse y describirse claramente. Un flujo ambiguo es aquel que transporta múltiples tipos de datos sin distinción. Si una sola flecha representa tanto el “ID de usuario” como el “Número de tarjeta de crédito”, la lógica está defectuosa porque estos elementos de datos tienen requisitos de seguridad y procesamiento diferentes.
Separar estos flujos garantiza que cada pieza de información se maneje de acuerdo con sus reglas específicas. La ambigüedad conduce a vulnerabilidades de seguridad y errores de procesamiento en etapas posteriores.
| Tipo de error | Indicador | Impacto |
|---|---|---|
| Conservación de datos | Los datos aparecen/desaparecen | Pérdida o corrupción de datos |
| Dependencia circular | Proceso A → Proceso B → Proceso A | Bloqueo del sistema |
| Proceso no conectado | Sin flechas de entrada o salida | Gasto de recursos |
| Inconsistencia en el almacén de datos | Lectura/escritura no controlada | Problemas de integridad de datos |
| Flujos ambiguos | Tipos de datos mezclados en un solo flujo | Riesgos de seguridad |
Metodologías para la detección 🛡️
Una vez conocidos los tipos de errores, el siguiente paso es establecer una metodología para encontrarlos. Una revisión pasiva a menudo es insuficiente. Se requiere una interrogación activa del diagrama.
Recorridos paso a paso 🚶
Realice un recorrido mental del diagrama. Comience desde una entidad externa y trace los datos a través de cada proceso hasta un almacén de datos o otra entidad. Haga preguntas en cada nodo. ¿Este proceso tiene suficientes entradas para funcionar? ¿Produce la salida esperada? Si yo ejecutara esta lógica, ¿a dónde irían los datos?
Este rastreo manual obliga al diseñador a visualizar el movimiento de datos de forma dinámica. Revela brechas que la visualización estática pasa por alto. Si el recorrido se atasca en un nodo, es probable que allí se encuentre el error lógico.
Sesiones de revisión entre pares 👥
Otra persona que analiza el diagrama aporta una perspectiva fresca. Un revisor puede detectar errores a los que el diseñador ya no presta atención por familiaridad. Anime a los revisores a cuestionar supuestos. Pídales que encuentren el flujo de datos que parece innecesario o faltante.
Las sesiones de revisión estructuradas reducen la posibilidad de omisiones. Se debe utilizar una lista de verificación durante estas revisiones para asegurarse de que se cubren todas las categorías de errores.
Reglas de validación automatizadas 🤖
Aunque no se nombra ningún software específico aquí, las herramientas de validación lógica pueden escanear diagramas en busca de errores estructurales. Estas herramientas pueden marcar nodos sin conexión, almacenes de datos faltantes o referencias cíclicas. Actúan como primera línea de defensa contra inconsistencias lógicas básicas.
El uso de comprobaciones automatizadas permite al equipo centrarse en la lógica de nivel superior en lugar de la sintaxis estructural. Asegura que la base sea sólida antes de añadir complejidad.
El costo de la negligencia lógica 💸
¿Por qué importa esto? Los errores lógicos en la fase de diseño son los más costosos de corregir. Si se descubre una falla lógica durante la codificación, se requiere reescribir módulos. Si se descubre después del despliegue, se requiere aplicar parches y posiblemente una migración de datos.
Considere la situación en la que un flujo de datos carece de una etapa de validación. Esto permite que datos inválidos ingresen al sistema. Más adelante, los informes generados a partir de estos datos son inexactos. La empresa toma decisiones basadas en información defectuosa. El costo de limpiar estos datos y restaurar la confianza es mucho mayor que el costo de corregir el diagrama inicialmente.
Además, los errores lógicos pueden provocar brechas de seguridad. Si un flujo permite que los datos eviten una verificación de seguridad, se expone información sensible. Esto puede derivar en violaciones de cumplimiento y consecuencias legales. Prevenir estos errores no se trata solo de eficiencia; se trata de gestión de riesgos.
Estrategias para la prevención 🛡️
La prevención es mejor que la detección. Implementar estándares y prácticas durante la creación del diseño de flujo reduce la probabilidad de que ocurran errores desde el principio.
Convenciones de nombrado estandarizadas 🏷️
Establezca reglas estrictas de nombrado para procesos, almacenes de datos y flujos. El nombre de un proceso debe ser un par verbo-nombre, como «Validar pedido». El nombre de un flujo debe describir los datos, como «Detalles del pedido». Esta consistencia facilita la detección de anomalías. Si un flujo se llama «Datos», es probable que sea demasiado genérico y debe ser revisado detenidamente.
El nombrado consistente también ayuda en la validación automatizada. Los scripts pueden analizar los nombres para verificar el cumplimiento con estructuras lógicas.
Diagramación por capas 📑
Descomponga los sistemas complejos en múltiples niveles. El nivel 0 muestra los procesos de alto nivel. El nivel 1 descompone esos procesos en subprocesos. Este enfoque jerárquico evita que el diagrama se vuelva caótico. El caos oculta errores lógicos.
Al enfocarse en áreas específicas, el diseñador puede centrarse en la lógica de ese subsistema específico sin perder de vista el conjunto. Los errores son más fáciles de detectar en vistas enfocadas.
Documentación de supuestos 📝
Cada diagrama viene con supuestos. Documentelos explícitamente. Si un proceso asume que los datos siempre están presentes, indíquelo. Si un flujo implica un retraso temporal, anótelos. Esta documentación proporciona contexto para los revisores. Aclara por qué se tomaron ciertas decisiones lógicas.
Cuando los supuestos se documentan, pueden ser cuestionados y validados frente a los requisitos del negocio. Esto reduce la posibilidad de que queden errores lógicos ocultos en el diseño final.
Lista de verificación de validación ✅
Antes de finalizar el diseño de un flujo, revise esta lista de verificación. Cubre las áreas críticas donde normalmente se ocultan los errores lógicos.
- Completitud de entradas: ¿Tiene cada proceso al menos un flujo entrante?
- Completitud de salidas: ¿Tiene cada proceso al menos un flujo saliente?
- Equilibrio de datos: ¿Se conserva el volumen de datos a través de los procesos?
- Sin caminos sin salida: ¿Existen procesos que no conduzcan a un almacén de datos o entidad externa?
- Nombres claros: ¿Todos los flujos y procesos tienen nombres descriptivos?
- Seguridad: ¿Los flujos de datos sensibles están claramente marcados y protegidos lógicamente?
- Sensibilidad temporal: ¿Existen dependencias de tiempo claramente definidas?
- Consistencia: ¿Los almacenes de datos coinciden con los datos utilizados en los procesos?
Perfeccionando el diseño 🎯
Una vez que se detectan errores, comienza el proceso de perfeccionamiento. Esto implica modificar el diagrama para corregir la lógica. No siempre se trata de eliminar elementos; a veces se trata de añadir conexiones faltantes.
Por ejemplo, si un proceso no tiene salida, determine a dónde deben ir los datos. Añada la flecha faltante al almacén de datos o entidad adecuados. Si existe una dependencia cíclica, introduzca un buffer o una cola para romper el bucle. Esto podría significar añadir un paso intermedio al diseño.
El perfeccionamiento es iterativo. Después de realizar cambios, vuelva a ejecutar la revisión y la lista de verificación. Asegúrese de que la nueva lógica resista el escrutinio. No asuma que la corrección está completa hasta que el diagrama pase todas las fases de validación.
Reflexiones finales sobre la integridad lógica 💡
La integridad de un diseño de flujo determina el éxito del sistema. Los errores lógicos son sutiles pero destructivos. Minan la confiabilidad de toda la arquitectura. Al aplicar métodos rigurosos de detección y estrategias de prevención, los diseñadores pueden crear sistemas que funcionen según lo previsto.
La atención al detalle durante la fase de diseño ahorra tiempo, dinero y esfuerzo en fases posteriores. Un diagrama bien validado es una plantilla para un sistema estable. Priorizar la consistencia lógica garantiza que los datos se muevan correctamente, de forma segura y eficiente a través de la organización. Este enfoque conduce a sistemas que no solo son funcionales, sino también resistentes al cambio. 🚀
Mantenga el enfoque en la claridad y la corrección. Cada flecha importa. Cada nodo cuenta. Al adherirse a estos principios, el diseño de flujo se convierte en un activo confiable para el equipo de desarrollo.